Financial Regulation / Content Risk Control / An anonymized securities-regulation RegTech project, in a content risk-control setting for securities supervision
A Domain LLM Training Toolchain for Illegal Securities Activity Detection
Illegal securities activity (stock-pumping jargon, guaranteed-return pitches, off-exchange margin funneling, fake licensed-institution claims, pre-IPO share scams) is scattered across 9 major social platforms and spans text, images, short video, and audio; manual patrol cannot keep up, while a general LLM neither understands the domain jargon nor explains its verdicts, so its judgments cannot be trusted or audited by regulators.
I led the engineering of a fully automated offline toolchain that cold-starts multimodal raw social data into training corpora and trains a domain LLM that judges illegal securities activity and states its reasoning in Chinese, built on Qwen3 with a three-layer anti-forgetting recipe of LoRA, general-corpus replay, and knowledge distillation; I also led the design of the online platform that consumes the model.
Multimodal data ingestion and cleaning -> domain lexicons + a unified recognition engine (normalize once, then fan out) -> rule + LLM + expert three-layer cold-start weak labeling -> training samples shaped as <think> reasoning + verdict -> a Qwen3 LoRA + replay + distillation anti-forgetting training recipe -> dual-track evaluation of domain accuracy and general-ability retention -> an overlay engineering architecture -> an online detection-platform design.
The offline training toolchain is built and runs end to end, locked down by hundreds of automated tests; a single command completes the full raw-data-to-cleaning-to-labeling-to-training-samples-to-evaluation pipeline in seconds on an ordinary CPU machine, no GPU required. The training and anti-forgetting configuration already passes LlamaFactory's real parsing checks, so a single command starts training once GPUs are available. The real model has not yet been trained, and verdicts shown in the demo come from the rule engine, representing recognition capability rather than trained-model performance.
This domain LLM training toolchain for illegal securities activity detection is a fully automated offline engineering system that cold-starts multimodal raw social data into training corpora and trains a domain model that judges illegal securities activity and states its reasoning in Chinese, built on Qwen3 with a three-layer anti-forgetting recipe of LoRA, general-corpus replay, and knowledge distillation.
Background
This was a content risk-control project for securities supervision. Stock-pumping jargon, guaranteed-return pitches, off-exchange margin funneling, fake licensed-institution claims, pre-IPO share scams — this kind of illegal securities activity is scattered in large volumes across major social platforms, in text, images, short video, and audio. Manual patrol simply cannot cover it all.
Pointing a general LLM at the problem has two hard flaws. It does not understand domain jargon like “follow the teacher’s calls / add my WeChat to join the group / guaranteed gains on pre-IPO shares,” so its false-positive rate runs high; and even when it judges correctly, it cannot explain why a post is illegal. In a regulatory setting, being explainable and auditable matters as much as being accurate.
The client identity is anonymized. What can be stated is the weight of the setting: a securities-regulation RegTech context, heavily regulated, requiring full multimodal coverage, with every verdict required to be auditable. The goal was never to call an API; it was to train a model that genuinely understands the language of securities supervision.
What Made It Difficult
The hard part was not any single technique. It was three obstacles stacked together, and you cannot clear any one of them in isolation.
The first: the data has no labels. Nobody tells you in advance which post is illegal and which is compliant. Supervised training cannot even take its first step — you want to train a model, and you hold not a single labeled sample.
The second: open models are not directly usable. General models lack domain knowledge; narrow-domain finance models trained hard on a small slice (such as DianJin-R1, Fin-R1) tend to fail under concept drift and carry an undisclosed risk of degraded general ability. Using them off the shelf means importing uncertainty into the one setting that most demands certainty.
The third: catastrophic forgetting. Teaching a model to judge securities content can easily degrade the general Chinese ability it started with. And “no catastrophic forgetting” was itself a hard requirement for this project — not a nice-to-have, but an acceptance line.
These three could not be picked off one by one with point tricks. The design of the whole system is essentially a systematic answer to all three.
My Role
I led the engineering of the entire offline training toolchain, and I led the design of the online detection platform. Let me keep the responsibility boundary clear: the offline toolchain is a built, working, test-locked deliverable; the online detection platform is currently a link-level design, not a running system in production.
On the offline side, what I built: unifying multimodal raw data from 9 platforms and 7 content types into a standard sample structure, chaining a data-juicer cleaning pipeline; decomposing short video into a three-path pipeline of keyframe extraction, speech transcription, and screenshot understanding; distilling domain knowledge into maintainable lexicons plus a unified recognition engine with a single entry point; designing the rule + LLM + expert three-layer cold-start weak labeling, with a guardrail so strong rules are never silently overridden by the LLM; making explainability a training objective in itself; selecting the Qwen3 base and configuring the LoRA + replay + distillation three-layer anti-forgetting recipe; hand-writing the dual-track evaluation with only the standard library; and choosing an overlay architecture that never forks upstream.
Approach and Tradeoffs
The whole thing is one main line with two cooperating layers. The offline toolchain cold-starts raw social data into corpora and trains the domain model; the online platform consumes the model to serve detection. The two layers share one set of domain knowledge and one explainability axis — domain knowledge labels data offline and does coarse screening online, same source; explainability is the reasoning section of the training target offline and the evidence chain plus trace records online, two ends of the same axis.
Cold-start weak labeling answers the “no labels” obstacle. Since nobody provides labels, three layers of joint judgment produce the first gold set: the rule engine assigns illegal / compliant / suspect labels by weighted signals (contact-info funneling carries the strongest weight, jargon density and promise pitches next), the LLM votes independently for consensus, and low-confidence samples are exported for expert review and fed back. There is a deliberate guardrail here — when a strong rule says “illegal” but the LLM majority disagrees, the system forces a “suspect” verdict and routes it to a human, never letting the LLM silently override a strong rule. In regulation, send more to humans rather than miss a violation. This is conservative; it gives up a little auto-clear rate to keep recall from being quietly sacrificed.
Three-layer anti-forgetting answers the “catastrophic forgetting” obstacle. The base did not start from an off-the-shelf finance model; it is the general Qwen3-14B/32B, with domain ability added on top through three stacked layers, all implemented in LlamaFactory’s native configuration without touching upstream source: LoRA trains only the attached low-rank patch and freezes the base (lora_rank: 32, lora_target: all); general-corpus replay interleaves general corpus at 85% / 15% (interleave_probs: 0.85,0.15); knowledge distillation (ASFT≈LwF, KL regularization, asft_alpha: 0.2) pulls back updates that stray too far from the frozen base. The design philosophy: solve it properly with the framework’s native capabilities first, add more only if that falls short, and put measurable verification ahead of stacking complex regularizers.
Making explainability a training objective answers “verdicts must be auditable.” The target output of a training sample is not a bare label but <think>{Chinese reasoning}</think>{final verdict}, reusing Qwen3’s native <think> chain-of-thought marker. The model states its reasoning first, then concludes. Explainability is not a feature bolted on afterward; it is the training objective itself, mapping directly to the per-verdict evidence chain and trace records on the online side.
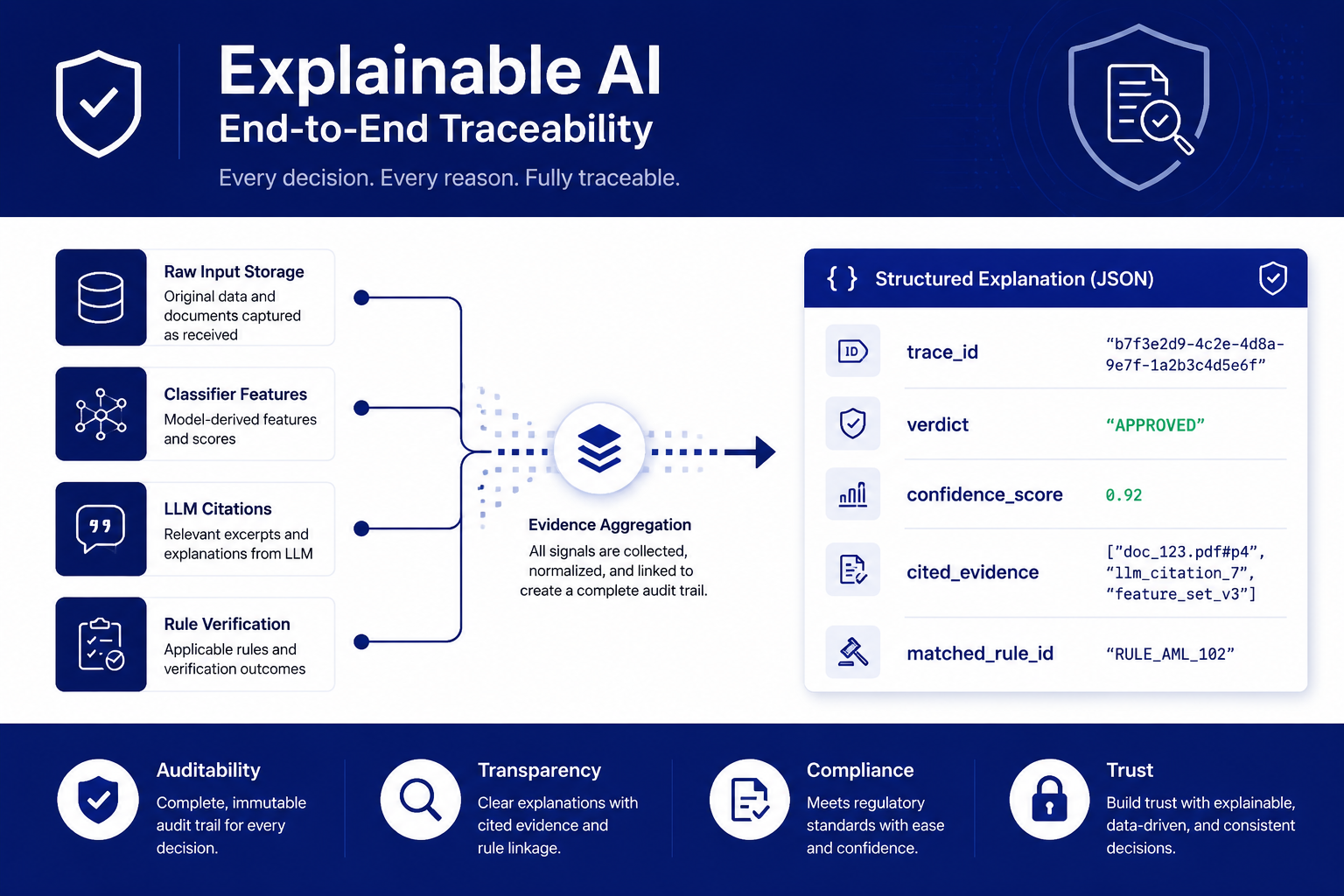
Online, every verdict is designed as a traceable structured explanation: source text, features, model reasoning, and matched rule pulled together. The verdict, confidence, trace_id, and matched-rule fields shown are illustrative of the structure; demo-stage values come from the rule engine and do not represent trained-model performance.
A few finer tradeoffs all point the same way: accept more engineering fragmentation in exchange for control and auditability. Short video does not go through an end-to-end video model; it is split into keyframe extraction, transcription, and screenshot understanding, with pHash capturing keyframes only when the scene changes, cutting frame count to a fraction of brute extraction — cheaper on compute and with each path independently traceable, at the cost of aligning three paths by frame index and timestamp. The recognition engine insists on normalizing once — NFKC full-to-half-width, zero-width stripping, and homophone restoration (威信→微信, 扣扣→QQ, 飞机→Telegram) happen once, then fan out to all detectors, so adversarial variants are caught consistently instead of leaving a gap where each detector normalizes its own way. Evaluation is hand-written with only the Python standard library, no sklearn or numpy, handling the two error-prone boundaries of unknown gold (not counted as FP) and excess gold (counted as FN) — regulation requires formulas you can recompute by hand, and pulling in a library is convenient but does not buy auditability.
Result and Boundaries
This section has to be stated plainly, because it is exactly what the credibility of this case rests on.
The offline training toolchain is built and runs end to end: data ingestion and multimodal cleaning, domain recognition, the cold-start weak-labeling and expert-review loop, the training and anti-forgetting configuration, the dual-track evaluation framework, and the one-command CPU end-to-end demo are all locked down by hundreds of automated tests. A single command runs the full “raw data → cleaning → labeling → training samples → evaluation” pipeline in seconds on an ordinary CPU machine, no GPU required, ready to demo to the business side at any time. The training and anti-forgetting configuration already passes LlamaFactory’s real parsing checks, so one command starts training once GPUs arrive. The overlay architecture held the “cannot ship an off-the-shelf open-source build” acceptance requirement: zero upstream modification, all domain work through official extension points.
But the real model has not been trained yet. It is waiting on two things: GPU compute (24–80G per card, sized for 14B or 32B) and an expert-reviewed gold set. Until then, the verdicts shown in the demo come from the rule engine and represent recognition capability, not the performance of a trained model. So this case carries no model-performance numbers — no accuracy, no recall, no false-positive reduction. Dressing up a rule-engine demo as model performance is not something I will do. The online detection platform (the three-stage text funnel, multimodal video understanding, RAG knowledge service, full-chain traceability) is likewise a link-level design at this point, not a running system.
What I Took Away
The easiest trap in AI for heavily regulated settings is mistaking demo results for delivered results. A rule engine can produce a clean verdict; that does not mean the trained model will perform at that level. Keeping the two separate looks like giving up a selling point in the short term, but in the long term it is the foundation these clients keep working with you on — a regulatory business knows better than anyone that a vendor who cannot state its own boundaries is the more dangerous one.
The other takeaway: in regulation, the engineering tradeoff almost always lands on the conservative side. Auto-clear rate, end-to-end convenience, stacking more elaborate regularizers — bonuses elsewhere — all yield here to auditability, hand-recomputable checks, and sending more to humans. Once that is clear, a lot of the technical choices stop being hard.
Related Links
If you are working on RegTech, content risk control, domain LLM training, or multimodal recognition, contact me by email at contact@aildnc.com. For China-based inquiries, use the WeChat QR code below the article.
Contact
Discuss Similar Work
If you are evaluating a similar document AI, enterprise RAG, knowledge base, or AI workflow project, share the context first. Email works, and Telegram is available for a faster reply: contact@aildnc.com.