Project
Domain LLM Training Toolchain for Illegal-Securities Detection
An offline training toolchain that cold-starts multimodal social-media data into a Chinese domain LLM that flags illegal securities activity and explains why.
This is an offline training toolchain. The input is noisy data from nine major social platforms, spanning text, images, short video, and audio. The output is a domain LLM that flags illegal securities activity and states its reasoning in Chinese, built on a Qwen3 base with three stacked anti-forgetting layers: LoRA, general-corpus replay, and knowledge distillation. It is not an API call and not a prompt demo. It is one engineering answer to three problems at once — no labels in the data, off-the-shelf models not directly usable, and catastrophic forgetting.
The project comes from a securities-regulation technology (RegTech) initiative. Illegal securities activity — coded stock-tipping jargon, guaranteed-return pitches, off-exchange margin funneling, fake licensed institutions, pre-IPO-share scams — is scattered across mainstream social platforms in four modalities, far beyond what manual review can cover. A general-purpose LLM used directly fails on two fronts: it does not understand domain jargon like “follow the teacher’s picks / add me on WeChat to join the group / pre-IPO shares, guaranteed profit,” and its false-positive rate runs high. A regulator needs more than accuracy; it needs auditable reasoning. Those are the two hard axes of the whole design.
I (Nie Er, AILDNC) led the engineering of the entire offline toolchain and led the solution design of the online review platform. One boundary up front: that online platform is a designed architecture, not a system in production, and the real model has not been trained yet. So this page carries no model-performance numbers. Any verdict you see in the demo comes from the rule engine — it reflects detection capability, not model performance.
Problem definition: three mountains
The regulatory work has to surface suspected illegal-securities content across nine platforms and four modalities, and each flagged item must explain why it is illegal — otherwise it cannot be trusted or pass an audit. Getting there means crossing three mountains first.
The data has no labels. Nobody tags the posts in the source data as legal or illegal up front, so supervised training has no starting point.
Off-the-shelf models are not directly usable. General models lack domain knowledge; existing finance-vertical small models (such as DianJin-R1, Fin-R1) tend to break under concept drift and carry an undisclosed risk of general-capability regression.
Catastrophic forgetting. Teaching the model to judge securities content can quietly degrade its original general Chinese ability — and “no catastrophic forgetting” is a hard requirement here, not a nice-to-have.
These three cannot be patched one by one with isolated tricks. The whole design is one continuous answer to all three.
Stack
The offline side is mostly Python. Cleaning chains data-juicer operators; keyframe extraction uses FFmpeg with pHash scene-change detection; Chinese speech-to-text uses Paraformer/FunASR; screenshot understanding uses Qwen3-VL with built-in OCR; the fine-tuning base is Qwen3-14B/32B, with LoRA + replay + distillation run through LlamaFactory; the dual-track evaluator is hand-written in the Python standard library, no sklearn/numpy. The online review-platform design also uses FinBERT for relevance pre-filtering and BGE-M3 + Elasticsearch 9 + BGE-Reranker-v2 for RAG knowledge services.

The pipeline splits into five model roles: text judgment (Qwen3), screenshot understanding (Qwen3-VL), speech transcription (Paraformer/FunASR), vector recall (BGE-M3), and reranking (BGE-Reranker-v2) — each doing only the part it is best at.
There is no public repository or hosted demo, so this page omits repoUrl and demoUrl. The public contact entry stays at the GitHub profile.
Architecture: one spine, two cooperating layers
The whole design is one spine with two cooperating layers. The offline training toolchain cold-starts raw social data into training samples and trains the domain model. The online review platform consumes that model to provide judgment capability. The two layers share one set of domain knowledge — labeling data offline, pre-filter verification online, same source — and share one explainability axis: offline it is the reasoning passage inside the training target, online it is the evidence chain and trace per verdict. Same axis, two ends.
The core offline modules:
1. Data ingestion and multimodal cleaning. The ingestion layer maps raw records from nine platforms and seven content types into one standard sample structure (text/image/video/audio fields plus provenance metadata). Cleaning chains data-juicer operators: strip HTML, normalize traditional-to-simplified (t2s), fix garbled Unicode, scrub privacy strings, then filter by language, by flagged-word ratio, by length, and finally deduplicate near-duplicate spam with SimHash.
Short video does not go through an end-to-end video model. It is split into three streams: FFmpeg decoding plus pHash scene-change detection grabs keyframes only when frame similarity drops below a threshold, cutting frame count to a fraction of brute-force extraction (24–30 fps); FFmpeg pulls the audio track for Paraformer/FunASR Chinese ASR, yielding timestamped text; keyframes go to Qwen3-VL to read subtitles, whiteboards, and stock codes. The three streams align by frame index and timestamp, and each evidence stream is independently traceable.
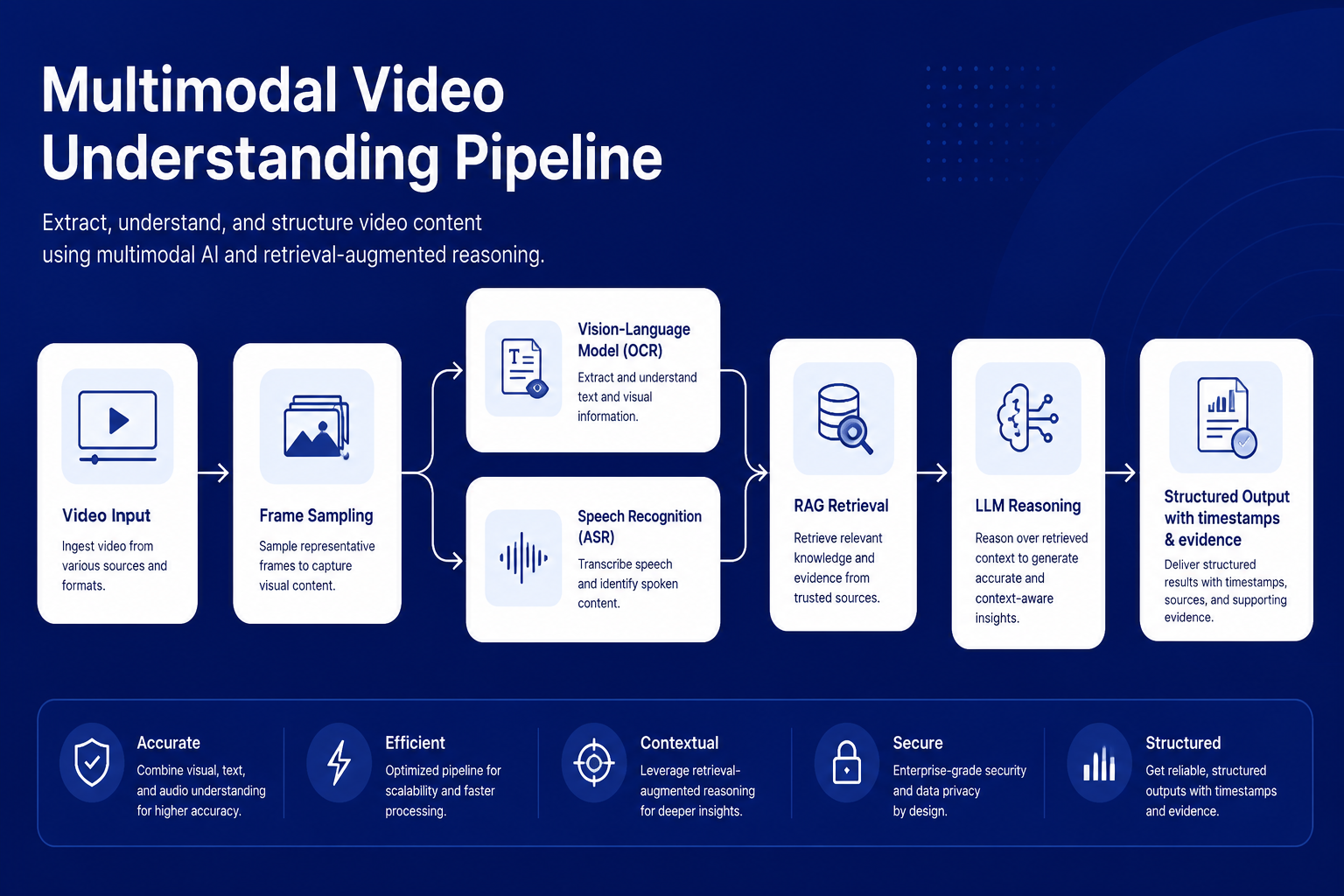
Short video is decomposed into three parallel streams — frame sampling, screenshot understanding (VLM/OCR), and speech transcription (ASR) — then merged into timestamped structured evidence, each stream traceable on its own.
2. Domain dictionaries and a unified detection engine. Domain knowledge is not hard-coded. It is distilled into five maintainable dictionaries (stock-tipping jargon, homophone variants, promise phrasing, risk entities, banned words), so extending the jargon is a one-line text edit. The detection engine exposes a single entry point: text in, a flat feature dictionary out (jargon density and hits, risk-entity counts, presence of contact info, promise-phrasing strength). Downstream labeling, training, and online pre-filtering all draw signals from the same entry, keeping them on one source.
3. Cold-start weak labeling. Because the data has no labels, three layers jointly produce the first gold set: rule scoring, LLM voting, and expert review. The rule engine assigns illegal/legal/uncertain labels by weighted signals — contact-info solicitation carries the strongest weight, jargon density and promise phrasing next. The LLM votes independently and forms consensus with the rules. Low-confidence samples are exported to experts and backfilled into the gold set.
4. Training samples and the explainability target. Weak-labeling output is converted to LlamaFactory’s alpaca format. Each sample’s target output is <think>{Chinese reasoning}</think>{final verdict}, reusing Qwen3’s native <think> chain-of-thought marker. The model must not only return illegal/legal/uncertain but also say why, in Chinese. Here explainability is the training target itself, not a feature bolted on afterward.
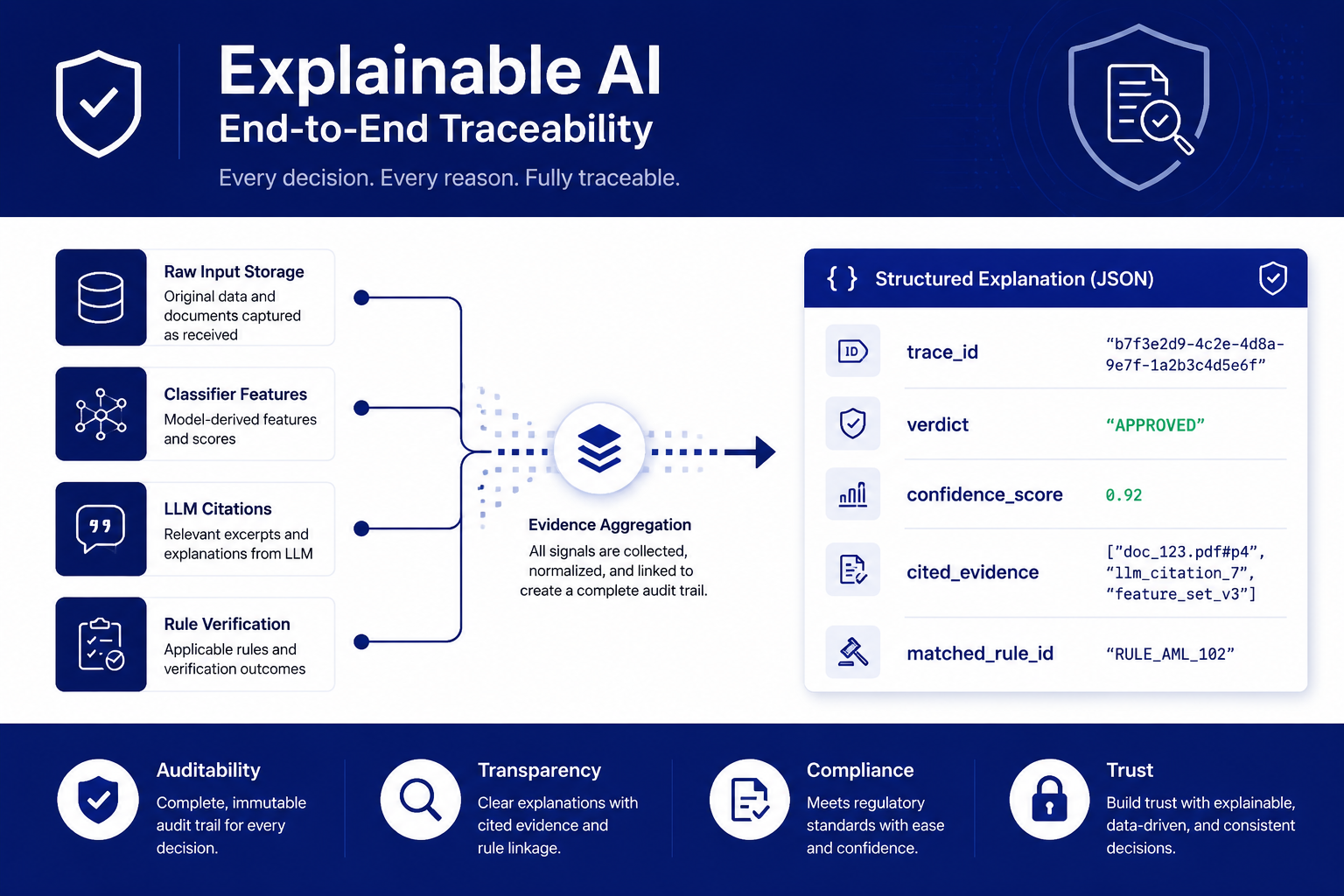
The online end of the same explainability axis: source text, features, model reasoning, and rule verification converge into one structured explanation. The verdict, trace_id, confidence, and matched-rule fields shown are illustrative of the structure; demo-stage values come from the rule engine, not from a trained model’s performance.
5. Base selection and three anti-forgetting layers. The base is Qwen3-14B/32B: strong Chinese financial reasoning, Apache-2.0 for commercial closed-source delivery, native thinking/non-thinking dual mode, first-class LlamaFactory support. The three anti-forgetting layers stack, all in native LlamaFactory config (no upstream source changes): LoRA incremental fine-tuning (lora_target: all, lora_rank: 32) freezes the base and trains only a side-attached low-rank patch; general-corpus replay (interleave_probs: 0.85,0.15) interleaves general corpus at 85%/15%; knowledge distillation (ASFT≈LwF, KL regularization, asft_alpha: 0.2) makes each step’s loss = task loss + α·KL(new model ‖ frozen base), pulling the model back when it drifts too far.
6. Dual-track evaluation. In a regulatory setting, “is the model usable” is two questions that must be measured separately. Domain accuracy: three-class precision, recall, and F1 on the gold set, plus a separate “reasoning-correctness rate” using character-level Jaccard between the model’s reasoning and the expert’s. General-capability retention: a set of securities-unrelated probes answered by base and tuned models, focused on regressions (could do it before, can’t after). The whole evaluator is hand-written in the Python standard library so the formulas can be hand-checked, with explicit handling of the unknown-gold (no FP) and excess-gold (counts FN) edge cases.
My role
- Designed and built the entire offline training toolchain: data ingestion and multimodal cleaning, domain dictionaries and the unified detection engine, cold-start weak labeling, training-sample generation, training recipe and anti-forgetting, dual-track evaluation, and the one-command CPU end-to-end demo.
- Designed short-video handling as a decomposed keyframe/ASR/screenshot pipeline to control downstream vision-model compute and keep each evidence stream traceable.
- Distilled domain knowledge into maintainable dictionaries plus a single-entry detection engine, making “normalize once, then fan out” the key defense against homophone variants.
- Designed the three-layer weak-labeling judgment with a guardrail: strong rules are never silently overridden by the LLM, and the system routes to human review rather than miss a violation.
- Made explainability the training target itself: samples output
<think>reasoning</think>verdict. - Selected the Qwen3 base and configured the LoRA + replay + distillation anti-forgetting stack without touching upstream framework source.
- Hand-wrote the dual-track evaluator in the standard library so both domain accuracy and general-capability retention become hand-checkable numbers.
- Led the overall architecture design of the online review platform (three-stage text funnel, multimodal video understanding, RAG knowledge service, end-to-end traceability) — a designed architecture, not a deployed system.
Challenges and trade-offs
Whether short video should use an end-to-end video model. An end-to-end model is convenient but expensive on compute and leaves evidence inseparable. I split it into three streams, with pHash grabbing keyframes only on scene changes, cutting frame count to a fraction of brute force — cheaper, and each evidence stream stays independently traceable. The cost is alignment work across the three streams by frame index and timestamp. In a regulatory setting that bargain is worth it: separable evidence matters more than saved engineering effort.
How to keep homophone variants from slipping through. If each detector normalized on its own, variants like 威信/微信, 扣扣/QQ, 飞机/Telegram would be handled inconsistently and miss detections. I centralized NFKC full-to-half-width conversion, zero-width stripping, and homophone restoration into a single pass before fan-out, so every detector sees the same normalized text. Risk-entity detection also embeds phone-number regex, six-digit A-share codes, and group-QR-code solicitation patterns. Contact-info solicitation is often the single strongest violation signal in a pitch, and inconsistent normalization is exactly how you lose it.
Which way the weak-labeling guardrail should lean. You could let LLM votes override the rules to chase a higher automation rate. But a regulatory setting would rather send more to humans than miss a violation. So when a strong rule says “illegal” and the LLM disagrees, the system forces “uncertain” and routes to review, with the uncertain confidence deliberately capped low to guarantee it reaches a human. This leans conservative and gives up some auto-clear rate, in exchange for not quietly sacrificing recall.
Whether to start from a finance-vertical model. Narrow-domain reinforced models like DianJin-R1 and Fin-R1 are strong in-domain but carry an undisclosed risk of general-capability regression, which conflicts with the no-catastrophic-forgetting requirement. I kept them as comparison baselines and built on a general Qwen3 base, adding domain ability back through the three anti-forgetting layers.
Whether domain adaptation should fork upstream. Forking gives the most freedom but means a painful merge on every upstream release. I chose the overlay pattern: the upstream data-processing and fine-tuning frameworks stay untouched, all domain changes live in my own package, hooked in only through each tool’s official extension points, so git pull keeps up. Inside the package one discipline holds — domain logic lives in a pure-stdlib core layer (unit-testable in seconds, no GPU, no heavy framework), and the framework-adapter layer is glue only.
Whether to pull in a library for evaluation. Importing sklearn/numpy saves code, but a regulatory setting requires hand-checkable, auditable formulas. I hand-wrote the three-class metrics and the four-quadrant forgetting matrix, with explicit unknown-gold / excess-gold handling. The cost is more code; the return is that every number can be hand-verified by the business side.
How to run it
The whole toolchain is guarded by hundreds of automated tests. One command runs the full raw-data → clean → label → samples → evaluate flow on a plain CPU dev machine in seconds — no GPU — so it can demo end to end for the business side anytime. The training recipe and anti-forgetting config already pass LlamaFactory’s real parser validation, so training can start with one command once GPUs are available: pick the 14B or 32B tier, 24–80G of VRAM per card.
What’s next
Real model training has not started yet; it is waiting on two things — GPU compute and an expert-reviewed gold set. Until both are in place, every demo runs on the rule engine and shows detection capability, not model performance, which is why this page carries no performance numbers. The online review platform is currently a designed architecture; if any module later lands as running code, I’ll note it separately.
Links
- GitHub: github.com/JV-X
If you are evaluating domain-LLM training for a regulated environment, multimodal content risk control, or a RAG knowledge service, contact me by email at contact@aildnc.com. For China-based inquiries, use the WeChat QR code below the article.