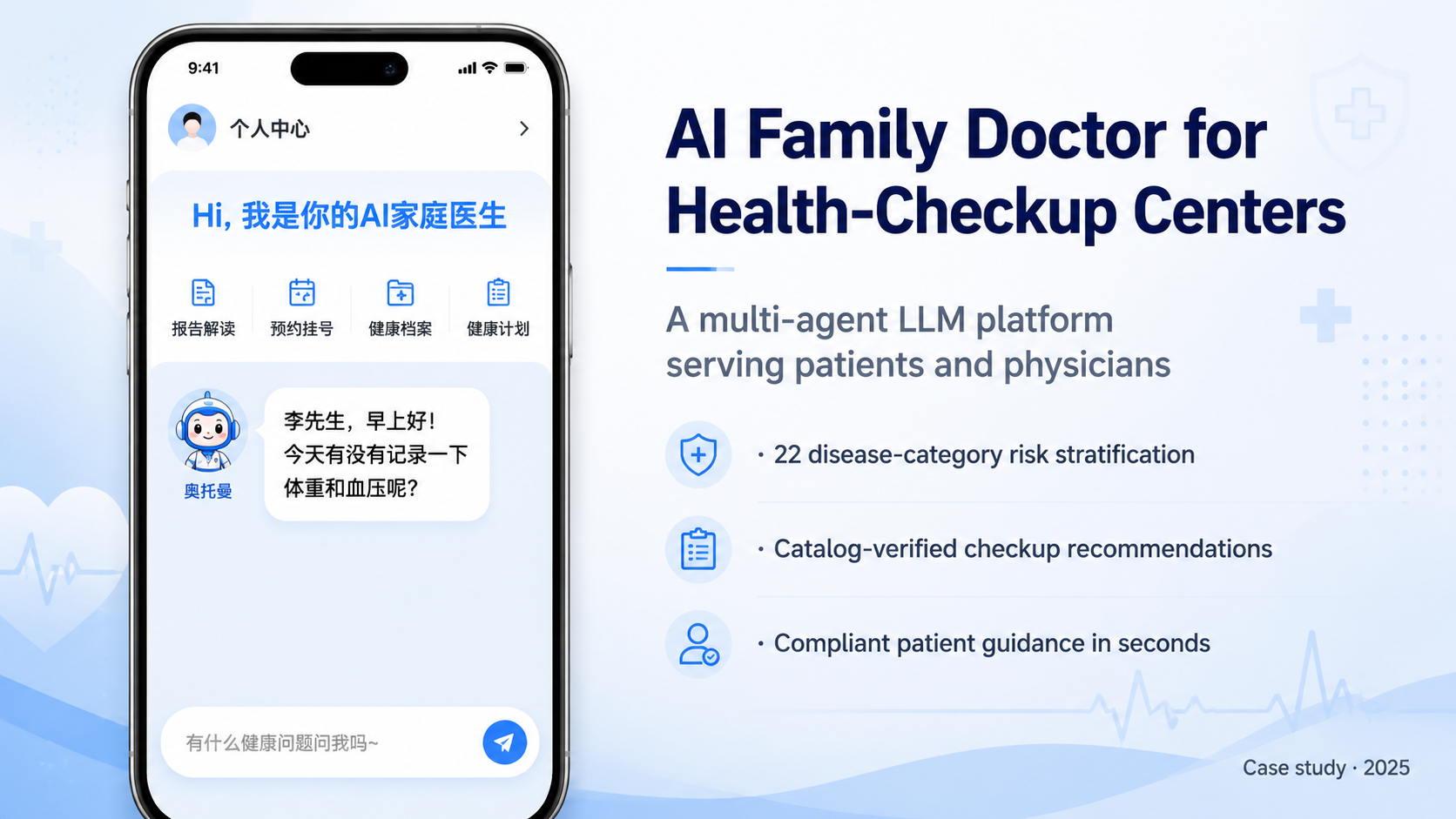
Healthcare / Preventive Care / An anonymized chain health-check provider serving hundreds of thousands of exam sessions in a year
AI Report Pipeline For Health Check Workflows
The real challenge was not generating text quickly, but keeping recommendation outputs, medical science copy, report advice, and contradiction checks inside operational and writing boundaries that a health-check institution could actually use.
I contributed to and maintained parts of the report pipeline by separating recommendation, explanation, advice, and contradiction detection into constrained flows, then tightening outputs with hospital-catalog validation, rule-based prompt control, and a multi-stage review chain.
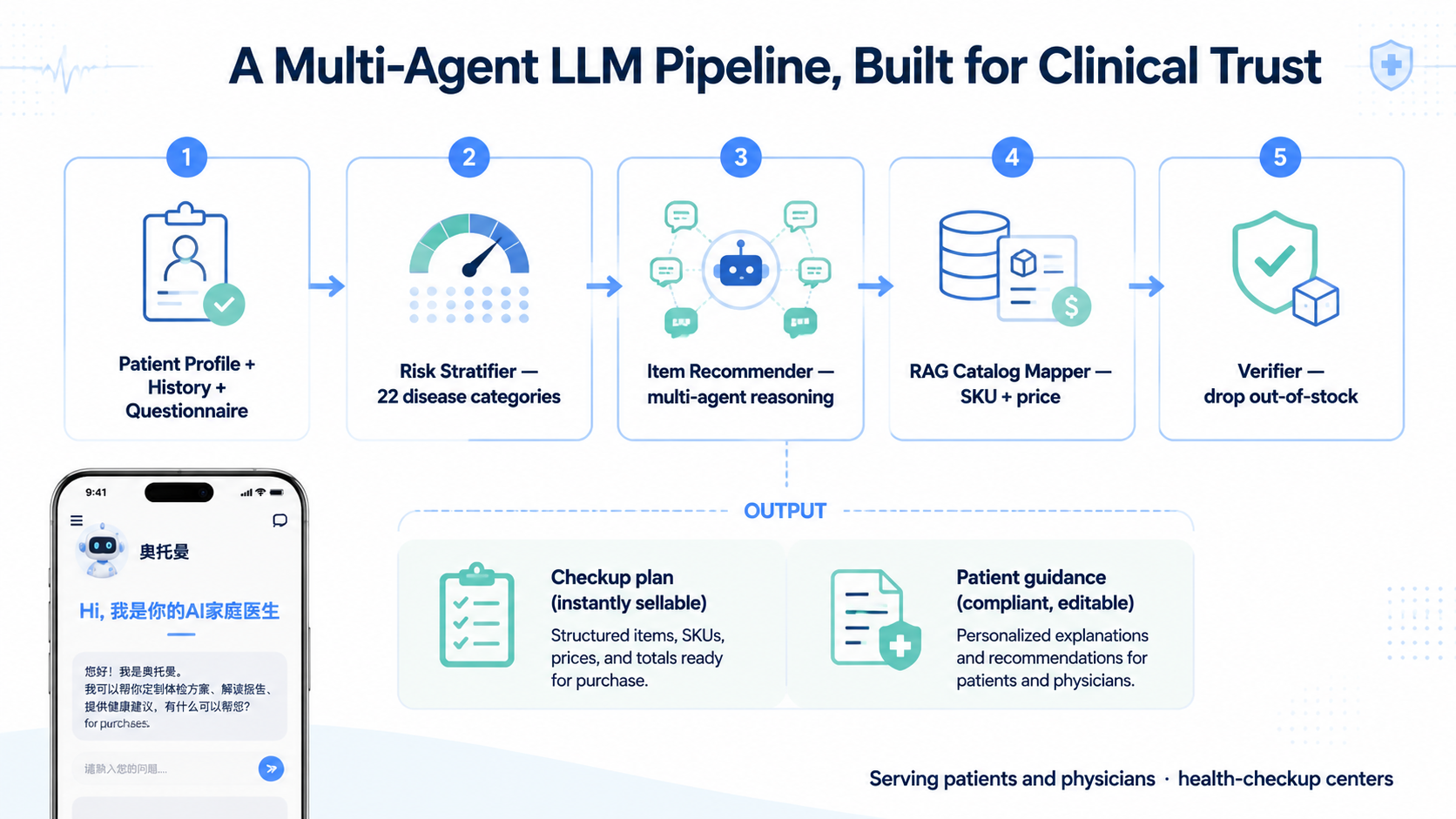
User profile and questionnaire -> recommendation reasoning, extraction, retrieval, mapping, and quality control -> constrained medical science and advice generation -> four-branch contradiction detection -> second-pass review and exemptions -> SSE response.
The pipeline established four production-oriented generation paths for recommendations, medical explanations, advice, and contradiction detection; recommendation outputs were checked against the institution catalog before fields could pass through, contradiction detection accumulated 13 named false-positive exemptions, and writing rules were formalized for both explanation and advice outputs.
In this kind of project, the hard part is not making a model produce a sentence. It is making sure a plausible sentence does not slip straight into a medical report without enough control around it.
Background
This work supported a chain health-check provider handling hundreds of thousands of exam sessions in a year. The system was not a general chat product. It sat inside a report pipeline with four different generation tasks: pre-exam item recommendation, report-stage medical explanation, report advice, and contradiction detection across report content.
The previous setup had little rule structure behind it. A single “explanation + advice” section took a doctor about three minutes to write manually. At that scale, the problem was not only labor. It was variation in writing style, unstable output boundaries, and the risk that a fluent but unsafe statement could enter a customer-facing report.
What Made It Difficult
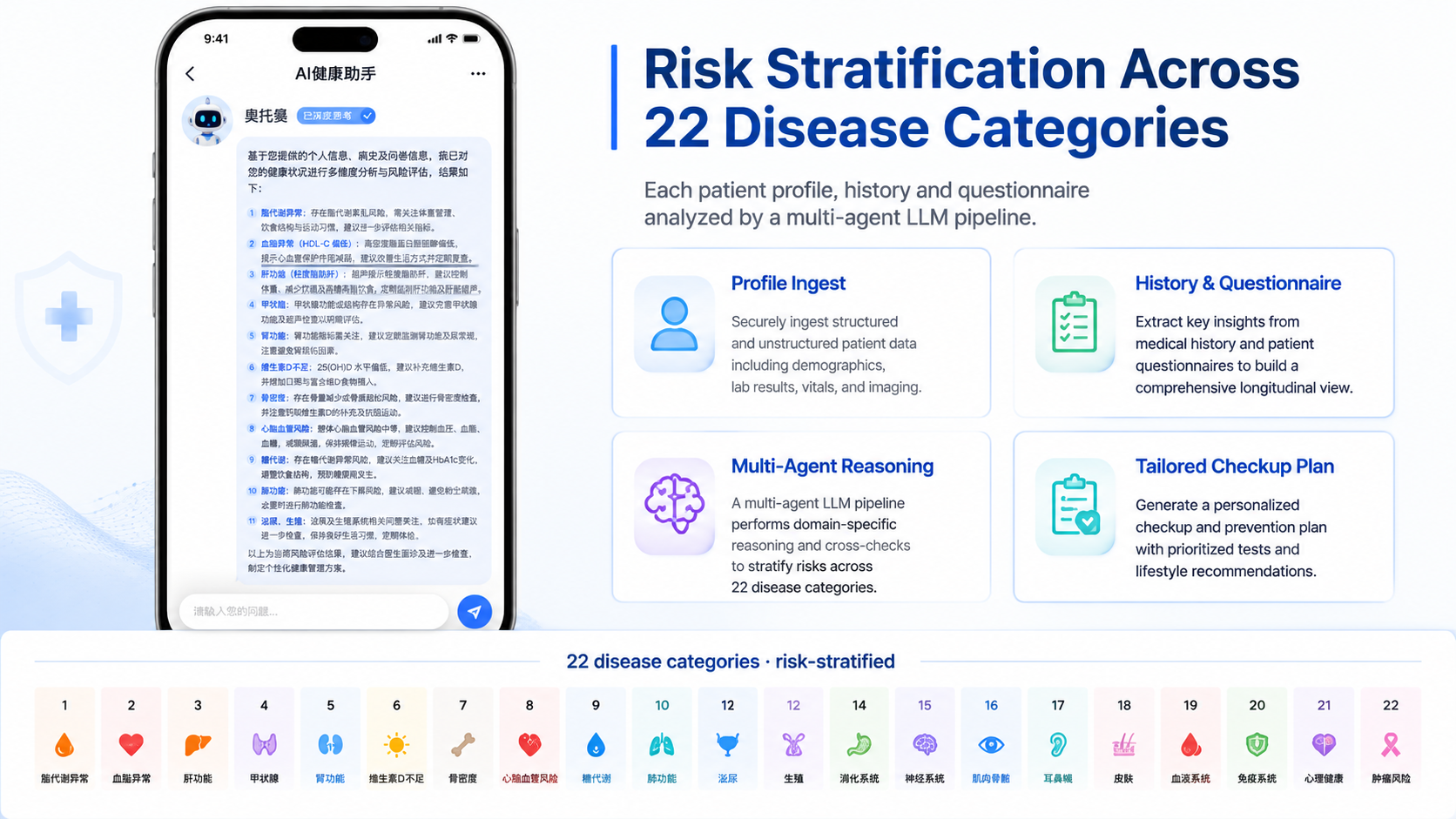
All four tasks involved generation, but each one failed in a different way.
Recommendations had to point to items the institution could actually provide, bill, and display. A model inventing a project code or price was not a cosmetic error. It could leak directly into the front end or the report workflow.
Medical explanation copy had its own boundary problem. Phrases that sounded comforting could still be unacceptable in this context. Statements like “no malignant possibility” or “no effect on normal lifespan” were treated as outputs to block, not because the system had already confirmed a complaint case, but because that tone creates the wrong kind of certainty in a health-check report.
Advice generation was partly a style-control problem. The issue was not only whether the advice was broadly reasonable, but whether it read like institution-grade report writing instead of ad hoc chatbot prose.
Contradiction detection was harder in a different direction. Many apparent contradictions in health-check reports are not true contradictions at all. They may come from template differences, medically compatible statements, or business rules. Blood pressure was one example: if one retest is normal, the business rule may allow a “normal” summary. A model that fixates on one abnormal measurement will over-report problems.
What I Worked On
My role here was deliberately narrower than “I led the entire system.” The confirmed public-safe facts support a B/C-level narrative: I contributed to and maintained parts of the pipeline rather than claiming end-to-end ownership.
On the recommendation side, I worked on splitting the flow into separate steps for reasoning, extraction, retrieval, mapping, and quality control. The key boundary was that the model could propose candidates, but it could not define the institution’s actual catalog. Generated item fields were checked back against the local project library, and mismatched identifiers, codes, or prices were cleared instead of being allowed to pass through.
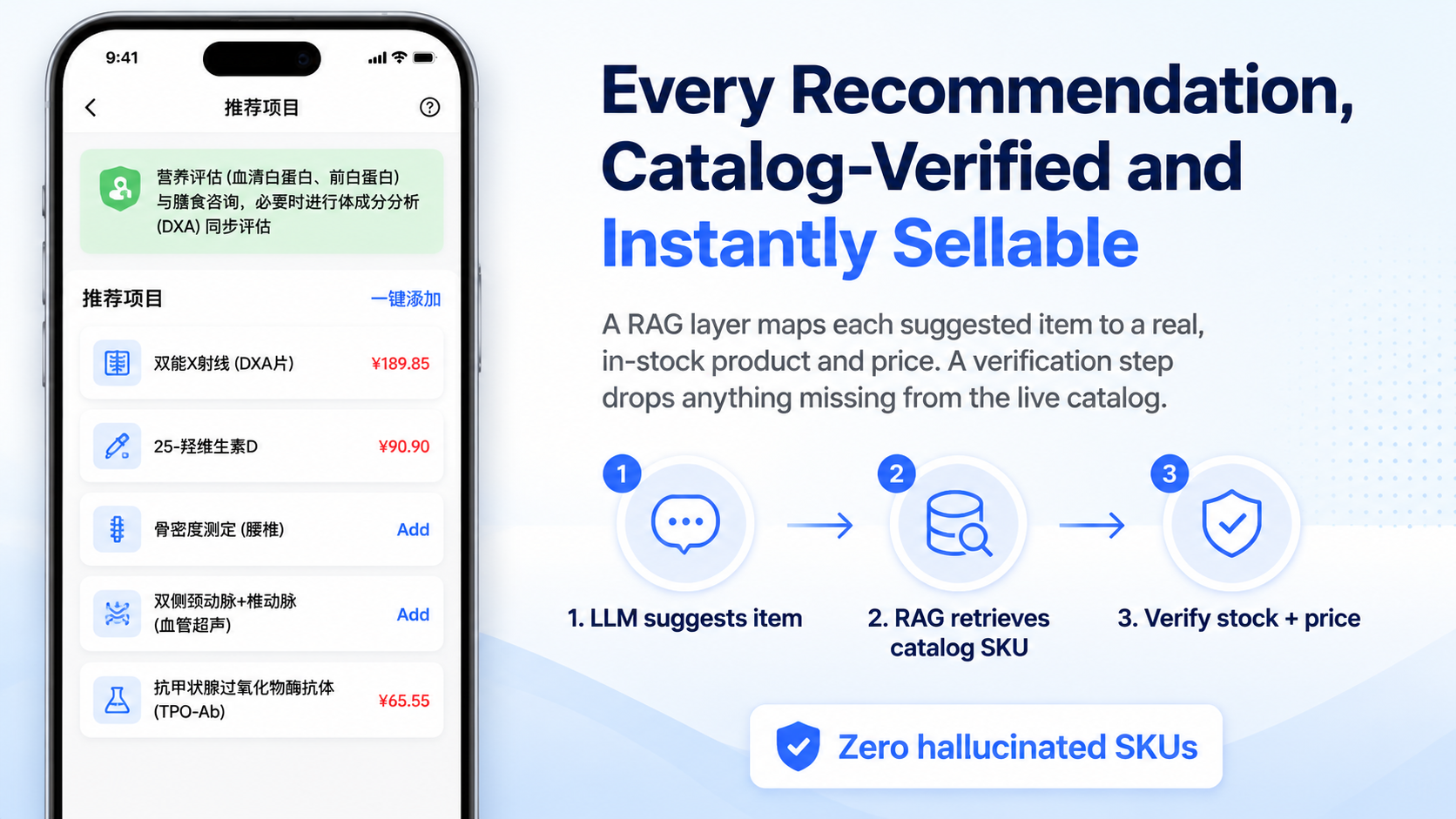
quality_control clearing fields on a mismatch.On the explanation and advice side, I helped maintain prompt rules that turned fuzzy writing expectations into explicit constraints. The explanation path included five hard banned expressions. The advice path enforced a narrower style: choose one advice type out of three, keep each advice line tied to one department, exclude emergency-department recommendations, and use Arabic numerals for follow-up timing.

On contradiction detection, I worked on maintaining a four-branch concurrent design and a three-stage LLM chain: natural-language analysis, structured JSON extraction, then a second-pass review with exemptions. The rule set accumulated 13 named false-positive cases over time, along with repeated handling for edge cases such as blood-pressure retest logic and reference-range boundaries.
Design Choices And Tradeoffs
The practical design choice was to avoid treating this as one giant prompt problem. Each path was constrained differently because each path had a different failure mode.
For recommendations, the model was allowed to suggest but not to finalize catalog truth. The quality_control step checked generated fields back against the institution’s known item relationships, and mismatches were cleared. That can lower apparent completeness, but it is a cleaner failure mode than passing invented codes or prices downstream.
For contradiction detection, the workflow did not stop at “ask the model whether this report is inconsistent.” It was split into analysis, structured extraction, and second-pass review. Structured outputs could retry up to five times, carrying the previous output back into context to reduce brittle JSON failures.
There was also an architectural tradeoff around orchestration. The project had earlier tried a heavier Coze-centered workflow. It later moved back to a combination where main inference ran through vLLM and Coze was kept for retrieval-style sub-workflows. The reason was not ideology. Most of the complexity here lived in business rules, exemption logic, and boundary control. Pushing too much of that into workflow nodes made orchestration itself part of the problem. In a later intranet deployment, Coze code-node sandbox cold starts of about three seconds per run made that tradeoff even easier to justify.
Another deliberate constraint was to disable some capability instead of forcing it into production too early. A historical contradiction branch was commented out because bringing longer history into context increased dilution and hallucination risk. In this case, a smaller scope was the better engineering choice.
Result And Boundary
The confirmed result is not “AI now fully writes medical reports on its own.” The available evidence does not support production coverage, error-rate, or labor-saving claims, so I did not write those in.
What can be said clearly is this: the pipeline established four constrained generation paths for recommendations, explanations, advice, and contradiction detection. Recommendation outputs were checked against the institution catalog before item identifiers, names, or prices could pass through. Contradiction detection accumulated 13 named false-positive exemptions and specific rule handling for cases such as blood-pressure retests and boundary-value interpretation. Explanation and advice outputs were also pulled into explicit writing rules instead of being left to model style alone.
That is the real value of the work I contributed to here. It turned several drifting generation tasks into constrained report-writing workflows with clearer operational boundaries.

If you are evaluating medical document generation, review chains, or agent workflows in high-risk domains, contact me by email at contact@aildnc.com. For China-based inquiries, use the WeChat QR code below the article.
Related Links
Contact
Discuss Similar Work
If you are evaluating a similar document AI, enterprise RAG, knowledge base, or AI workflow project, share the context first. Email works, and Telegram is available for a faster reply: contact@aildnc.com.