Article
In Health Check AI, Generation Is The Easy Part
A practical engineering note on why health check AI pipelines need hard boundaries for recommendation mapping, report wording, contradiction review, and workflow design.
When people talk about AI in healthcare workflows, the first instinct is often model quality: should the model be stronger, should the prompt be more detailed, should the workflow be more elaborate?
In a health check report pipeline, that is usually the wrong starting point.
I worked on and maintained part of an AI reporting pipeline for a chain health check provider handling hundreds of thousands of annual checkup sessions. The system was not a chat assistant. It covered four linked generation tasks: recommendation, health education, follow-up suggestion, and contradiction detection. In practice, the hardest part was rarely getting the model to say something. It was preventing the system from saying the wrong thing in a form that looked trustworthy.
The Main Problem Is Not Fluency
In the previous generation of the process, the health education and suggestion sections were still written manually by doctors, about 3 minutes per report. At that scale, the bottleneck was not just labor. It was inconsistency in writing style, inconsistent report boundaries, and the risk that a model might invent a project code, produce an over-reassuring sentence, or flag a harmless report difference as a serious contradiction.
That changes the design goal.
The first question is not how to make the output read more naturally. The first question is how to block a few classes of failure:
- recommendations must map to real in-house items, not just plausible names
- health education must not drift into implied medical reassurance
- suggestions must read like institutional report writing, not chatbot prose
- contradiction detection must separate true conflicts from medically coexisting differences
Without those controls, a smoother model is just a smoother way to make mistakes.
Recommendation Is A Mapping Problem, Not Just A Reasoning Problem
One of the easiest mistakes in this kind of system is treating “good recommendation” and “deployable recommendation” as the same thing.
The recommendation flow was split into stages instead of asking the model for a final answer in one shot. It went through reasoning, extraction, retrieval, mapping, and quality control. The model first produced recommendation logic, then extracted project names, then retrieved relevant in-house items, and only then mapped those results into usable fields.
The important guardrail was quality_control. The system checked the model output projectId, projectCode, and projectName against relation_items. If they did not match, it cleared projectId, projectCode, and projectPrice.
That sounds conservative, and it was meant to be. In a report pipeline, it is much better to show less than to let a hallucinated code or price pass through as if it were real.
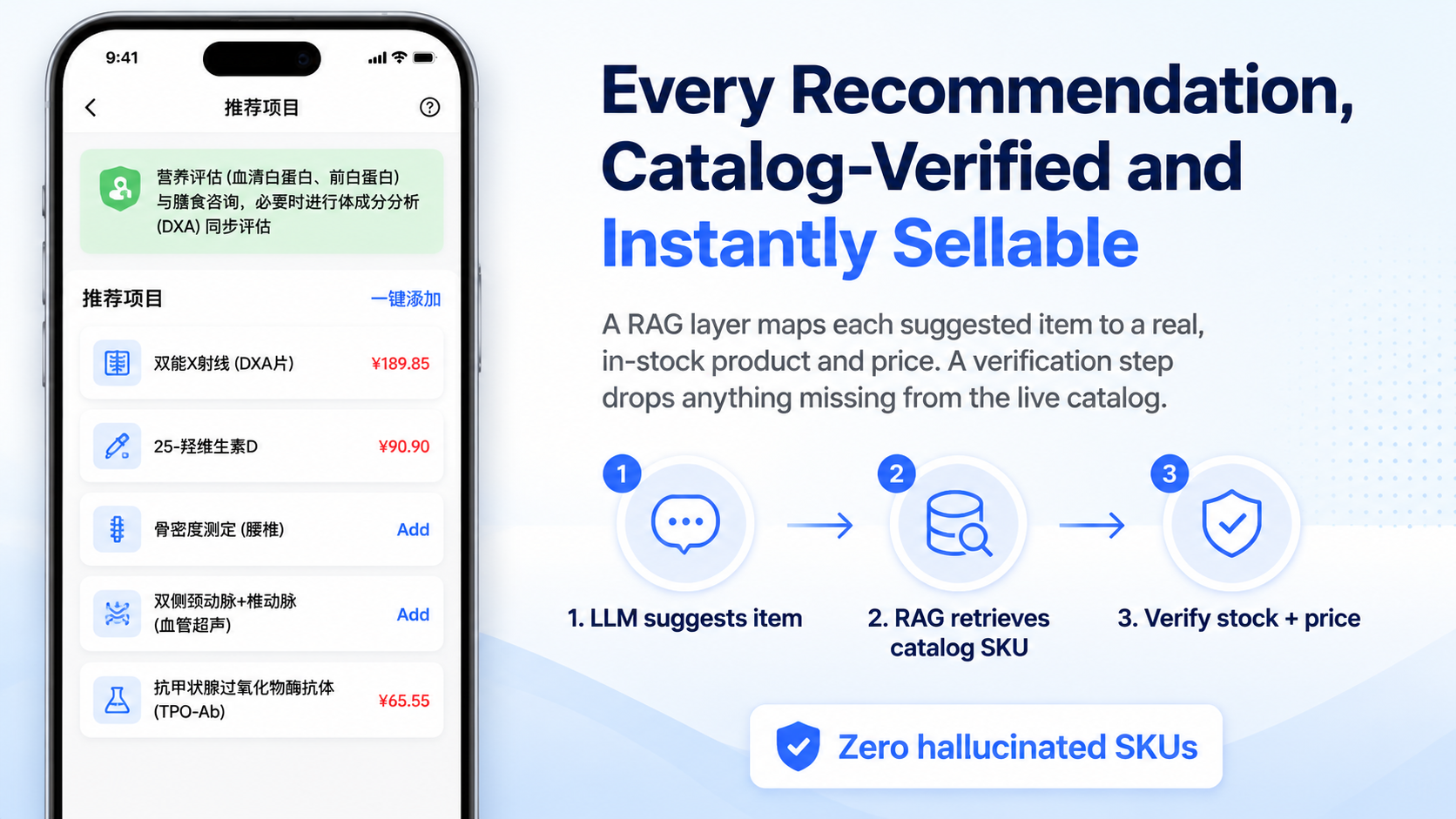
The recommendation side also maintained more than twenty special screening categories and evaluated them concurrently with ThreadPoolExecutor(max_workers=20). That kept latency manageable, but it also meant the rule table had to stay under active maintenance as business coverage changed.
Health Education And Suggestions Behave More Like Rule Systems Than Writing Tasks
These sections can look like pure writing problems from the outside. They are not.
A common instinct is to use a few good doctor-written examples and let the model imitate the tone. I do not trust that approach very much in this setting. Few-shot examples influence style, but they also pull in concrete disease descriptions, body parts, and numbers in ways that are harder to control.
A rule-first approach was more stable here.
On the health education side, there were 5 hard banned phrases, including wording equivalent to “no malignant possibility” or “does not affect normal lifespan.” The point was not that every such phrase had already caused a confirmed complaint. The point was that once this type of reassurance enters a health check report, the report starts making promises it should not make.
The suggestion side had more structural rules:
- every suggestion had to fall into one of three types: specialist visit, further examination, or follow-up review
- one suggestion could belong to only one department
- emergency department suggestions were explicitly excluded
- time ranges had to collapse to the shortest interval
- numbers had to be written in Arabic numerals
These are not glamorous rules, but they determine whether the result feels like institutional medical writing or like a generic assistant response.

Contradiction Detection Gets Expensive When False Positives Pile Up
Contradiction detection sounds straightforward if you describe it abstractly: compare statements and find conflicts.
Actual health check reports are messier. Many text differences that look inconsistent are medically compatible. That is where false positives become more damaging than missed elegance.
The contradiction flow was organized into four branches: cross-department, cross-department gender-related, within-department, and historical comparison. The historical branch was later disabled because long context made attention quality worse. Each active branch used a three-step LLM chain:
- natural-language analysis of possible conflicts
- structured JSON extraction
- second-pass review and exemption handling
The JSON stage retried up to 5 times, feeding the previous model output back into context when formatting failed. It was not a beautiful design. It was a practical response to model and infrastructure limits at the time.
The more important layer was exemptions. The system accumulated 13 named false-conflict exemption cases for recurring reporting patterns.
One telling example was blood pressure retest logic. A raw measurement could be abnormal, the first retest could still be abnormal, and a later retest could be normal. In the business rule, one normal retest was enough to treat the result as normal. If the model fixated on the first abnormal values, it would mark the summary as contradictory. That kind of error does not disappear just because the model is more fluent. It has to be encoded into prompts and review logic.
Heavy Workflow Platforms Are Not Always The Right Center
This project also went through a phase of trying to push more logic into Coze-style workflow orchestration. The eventual trade-off moved back toward a simpler split: vLLM for the main reasoning path, workflow tooling mainly for retrieval-oriented subflows.
The reason was practical. The hard part of the business was not node wiring by itself. It was recommendation fit, medical boundary handling, false-positive control, and report wording. If all of that is pushed into the workflow layer, the orchestration becomes its own source of complexity.
There was also a concrete operational clue. In the client intranet deployment, cold starts for Coze code-node sandboxes were about 3 seconds per invocation. Once you see that kind of overhead, the architecture question becomes much clearer: which steps truly benefit from the platform, and which should stay in a more controlled service layer.
The Practical Lesson
For health check AI, I would not frame the problem as “build a smart assistant.” It is closer to building a constrained content pipeline with medical and operational boundaries baked in.
The real engineering questions are things like:
- how recommendations map back to the real item catalog
- which report wording is never allowed
- how writing style stays stable across outputs
- how recurring false conflicts get turned into explicit rules
- how long context, retries, and concurrency affect latency and failure modes
That is where the system becomes usable. Not when one output looks clever, but when the pipeline keeps its boundaries over time and stays maintainable as business rules evolve.
If you are evaluating an enterprise RAG, knowledge base, AI support, or agent workflow project, visit https://www.aildnc.com or contact me by email at contact@aildnc.com. For China-based inquiries, use the WeChat QR code below the article.