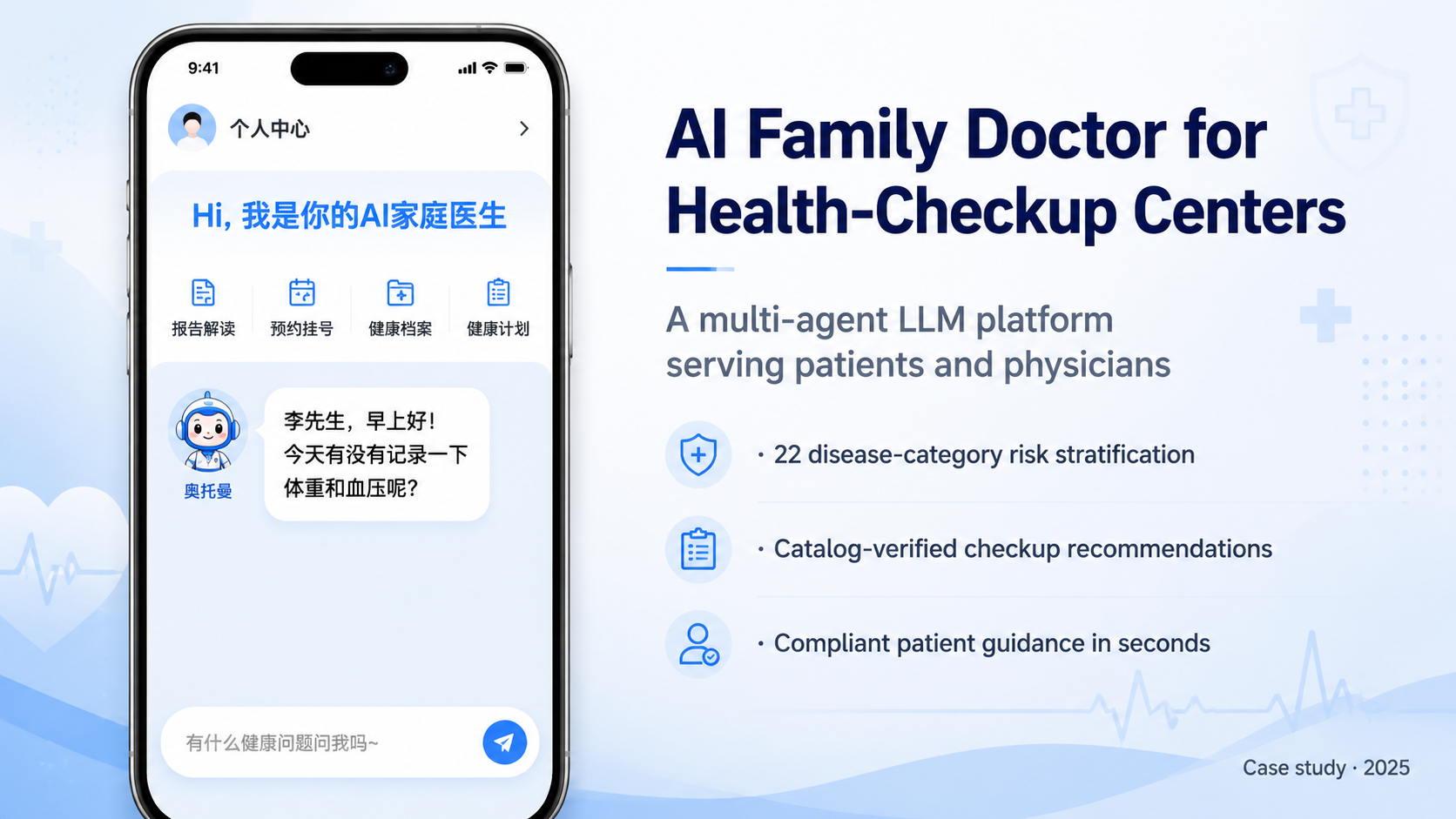
Project
Health Check Report AI Assistant
A report-pipeline AI project for a large health check provider, covering package recommendation, medical education, recommendations, and contradiction detection.
This project was built for a chain health check provider handling hundreds of thousands of annual exams. It was not a consumer chatbot. The useful part was a set of generation workflows embedded into the reporting pipeline: package recommendation before the exam, then medical education, doctor-style recommendations, and contradiction detection during report generation.
My role here was closer to participating in and maintaining parts of the workflow than owning the whole system end to end. I am keeping that boundary on purpose. This page focuses on the modules, controls, and engineering decisions I can support from the confirmed public-safe material.
Problem
The hard part was never “make the model write medical text.” The hard part was getting model output into a formal report workflow without creating new risks.
- A recommended exam item had to map to something the institution could actually offer and bill for.
- Education text could not drift into reassurance or medical promises.
- Recommendation text needed to sound like institutional report language, not a chat reply.
- Contradiction detection had to separate real conflicts from findings that can coexist in normal medical reporting.
In the earlier generation of the workflow, one piece of “education + recommendation” content still took a doctor about 3 minutes to write manually. At scale, the real engineering question became how to break that work into constrained, reviewable modules.
Architecture
The public-safe version of the workflow can be described as four modules.
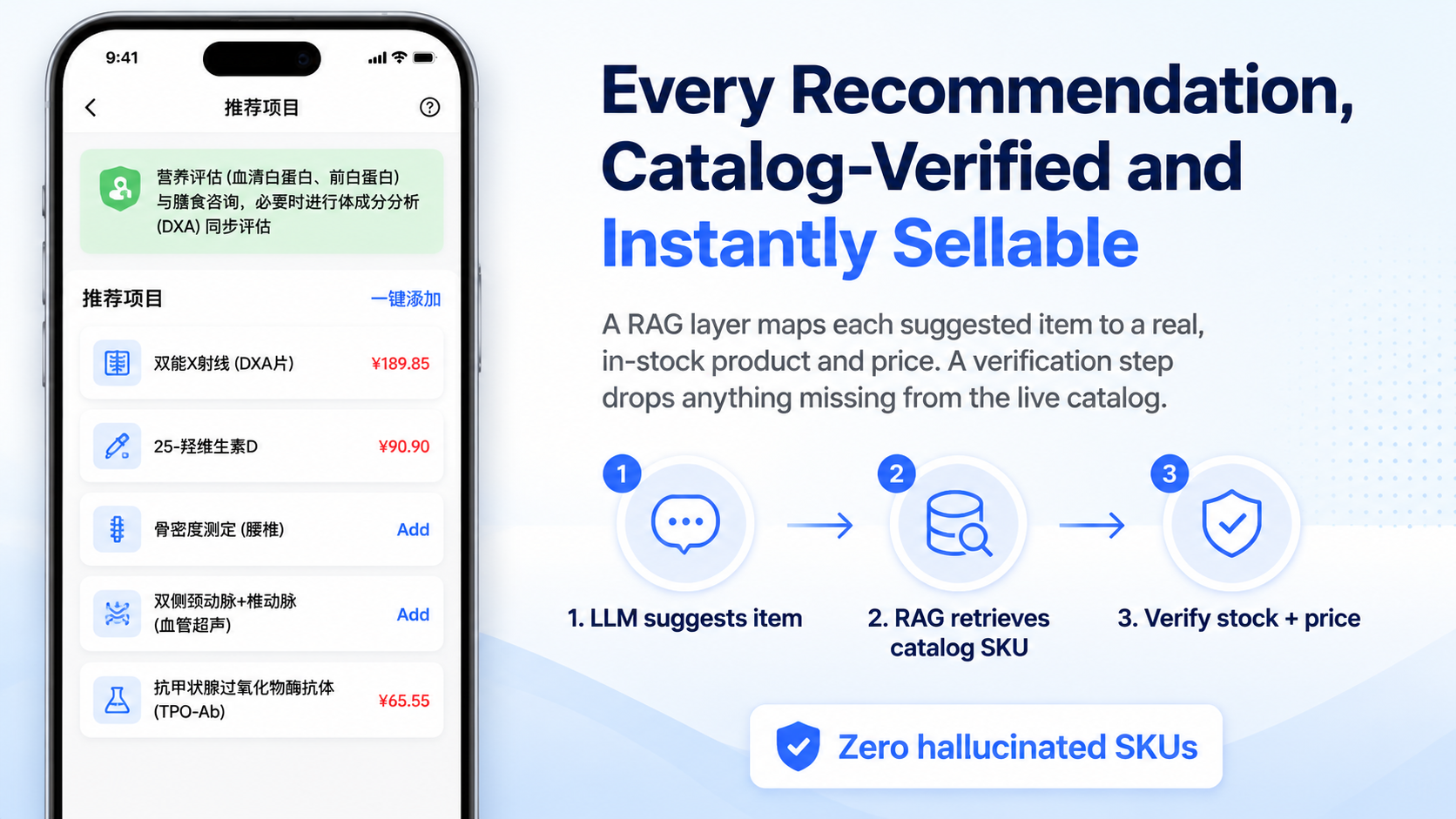
Package recommendation
The system did not ask the model to emit final exam items in one shot. The flow was broken into several steps:
- Generate reasoning about the user profile and recommendation direction.
- Extract candidate item names from natural language.
- Run parallel retrieval-oriented sub-workflows to find institution-specific items.
- Map candidates to local item fields.
- Run
quality_controlagainst the local catalog and clear key fields when the mapping does not hold.
That last step matters. It is better to lose a questionable recommendation than to let a fabricated item code or price reach the report layer.
Medical education and recommendations
These outputs were configuration-driven rather than tied to one frozen prompt. The rule layer did a lot of the real work:
- The education module had 5 hard banned phrases to block promise-like or overly reassuring wording.
- The recommendation module allowed only 3 output types: specialist visit, further examination, or follow-up.
- One recommendation could belong to only one department.
- Follow-up time ranges were normalized to the shortest interval, and numbers had to use Arabic numerals.
- Emergency department advice was explicitly excluded.
This was less about fluency and more about keeping the report voice controlled and institutionally consistent.
Contradiction detection
Contradiction detection ran in 4 parallel branches: inter-department, inter-department by gender, intra-department, and historical comparison. The historical branch was later disabled because long context windows diluted model attention too much.
Each branch used a 3-stage chain:
- Natural-language analysis of possible conflicts.
- Structured JSON extraction.
- A second-pass review and exemption stage to remove medically acceptable coexistence cases.
The workflow also accumulated 13 named false-contradiction exemptions and added explicit handling for cases such as blood pressure retest logic.
Workflow platform trade-off
The project initially explored a heavier Coze workflow approach, then moved back toward “vLLM for core reasoning, Coze only for retrieval-like sub-tasks.” The reason was practical: the deepest complexity was in recommendation fit, business rules, and false-positive control, not in visual workflow orchestration. On the client intranet deployment, Coze code-node sandbox cold starts of about 3 seconds per run made the orchestration layer itself part of the latency story.
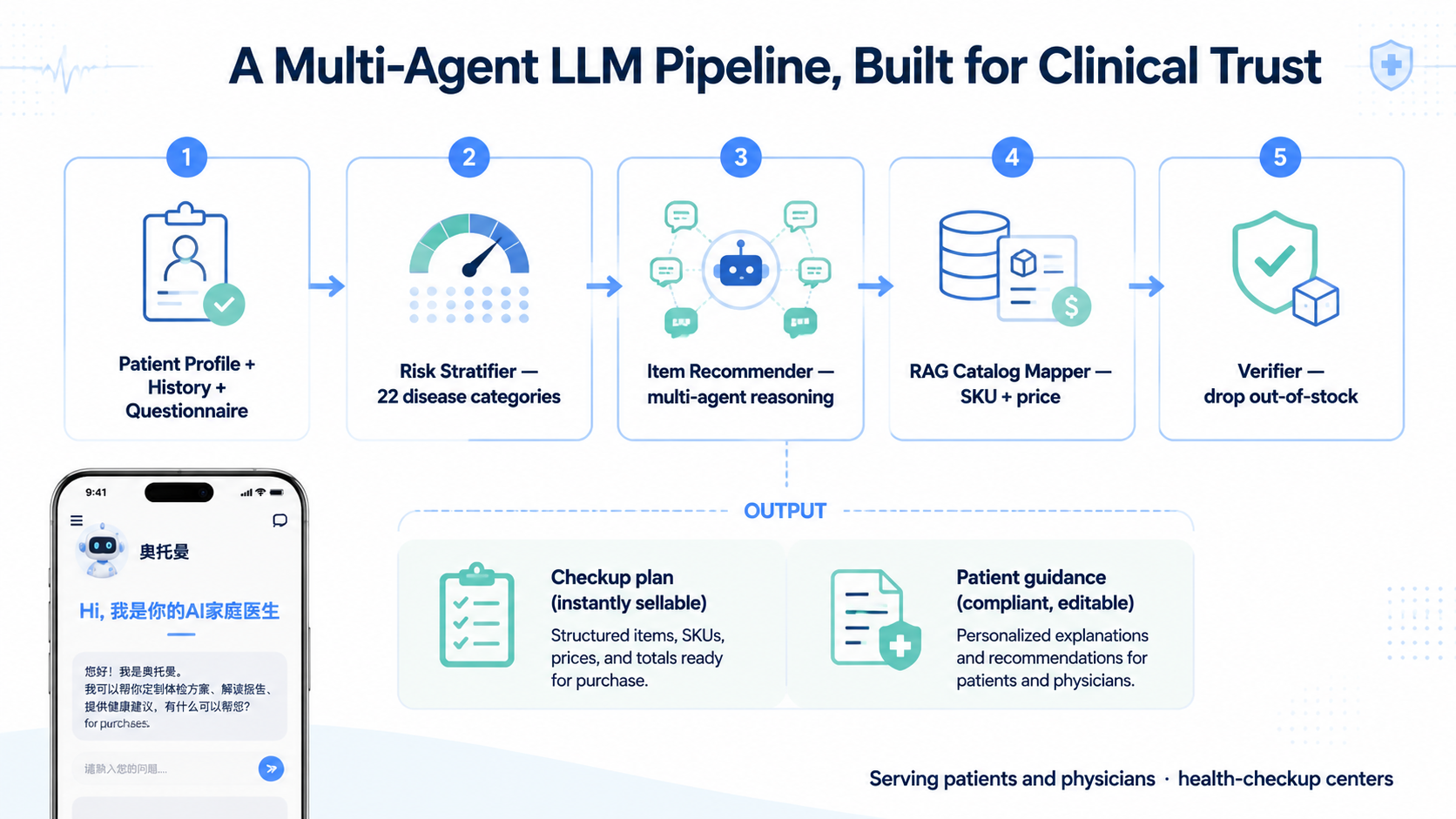
What I Worked On
The parts I can describe with confidence are:
- Participating in and maintaining the engineering review of all 4 generation paths: package recommendation, education, recommendations, and contradiction detection.
- Preserving the staged design of the recommendation path: reasoning, extraction, retrieval, mapping, and quality control.
- Reviewing the
quality_controllogic that checks model output against the institution catalog and clears unsafe fields on mismatch. - Reviewing the contradiction flow with 4-way parallelism, a 3-stage LLM chain, 5 JSON retries, and 13 exemption cases.
- Reviewing the prompt constraints for education and recommendations, including banned phrasing, output-type restrictions, department ownership, and time-format rules.
- Contributing to the engineering judgment that moved the system away from a workflow-heavy Coze design toward a core-reasoning-plus-retrieval split.
I am deliberately not turning institution rules, physician judgment, or full-team delivery into a personal hero story here.
Hard Parts and Decisions
Hallucinations could not be allowed to reach the report.
That is why the recommendation flow ends with catalog validation. If an item cannot be matched back to the institution inventory, key fields are cleared. It lowers recall, but it keeps fabricated identifiers and prices out of downstream output.
Long prompts and long context reduced reliability.
The contradiction chain used up to 5 JSON retries, feeding the previous failed output back into context. It is not elegant, but under the model and compute limits of the time, it was a workable way to reduce structured-output failures.
Medical report tone could not rely on few-shot examples alone.
Few-shot examples are useful until they start leaking concrete disease names, body parts, or numbers into the wrong place. In this workflow, rule-based style constraints were the more stable option.
False positives had to be handled as an engineering system, not just a prompt tweak.
The contradiction module eventually kept a white-list style exemption set. That approach is imperfect, but it turns repeated business pain into explicit control logic.
Next Steps
Based on the confirmed project facts, the most obvious follow-up work would be:
- Separate rule logic and model logic more cleanly, so prompt changes do not create such a large regression surface.
- Add stronger structured-output constraints to reduce dependence on repeated JSON retries.
- Revisit the disabled historical contradiction branch with better context management.
- Keep workflow tooling limited to the retrieval tasks it fits best, instead of pushing business logic into orchestration for its own sake.
The main lesson I carried from this project is simple: in medical-adjacent generation systems, shipping depends less on whether the model can write and more on whether validation, boundaries, and fallback behavior are strong enough.
If you are evaluating an enterprise RAG, knowledge base, AI support, or agent workflow project, contact me at contact@aildnc.com or through aildnc.com. For China-based inquiries, use the WeChat QR code below the article.