项目
非法证券活动识别领域大模型训练工具链
把社交平台多模态脏数据冷启动加工成语料、训出一个会判定非法证券活动并能说出判定依据的中文领域模型的离线训练工具链。
这是一条离线训练工具链:输入是 9 个主流社交平台、横跨文本/图片/短视频/音频的脏数据,输出是一个会判定非法证券活动、并能用中文说出判定依据的领域大模型,底座为 Qwen3,配 LoRA + 通用语料回放 + 知识蒸馏三层防遗忘。它不是调一个 API,也不是一个 prompt demo,而是把「数据没标签、开源模型不直接可用、灾难性遗忘」三个问题一次性系统性回答掉的一整套工程方案。
这个项目来自某证券监管科技(RegTech)课题。荐股黑话、保本保收益话术、场外配资引流、虚假持牌机构、原始股诈骗这些非法证券活动,大量分散在主流社交平台上,形态横跨四种模态,人工巡检根本看不过来;而通用大模型直接拿来判,既不懂「老师带单 / 加 V 进群 / 原始股稳赚」这类领域黑话,误报率也偏高。监管场景要的不只是判得准,还要判得出依据、可被审计——这是整套设计的两条硬轴。
我(聂二,AILDNC)主导整条离线工具链的工程实现,并主导在线研判平台的方案设计。需要先说清楚边界:研判平台目前是链路方案设计,不是已上线运行的系统;真实模型也尚未训练,下文不会出现任何模型效果数字,演示里的判定结果来自规则引擎,代表的是识别能力,不是模型性能。
问题定义:三座山
监管业务要在 9 个社交平台、4 种模态的海量内容里筛出涉嫌非法证券活动的内容,且每一条都要能说清「为什么判它违法」,否则无法采信、无法过审计。要做到这点,先要翻过三座山。
数据没有标签。 数据源里的帖子,没人事先告诉你哪条违法、哪条合规,监督训练无从起步。
开源模型不直接可用。 通用模型缺领域知识;现成的金融垂类小模型(如 DianJin-R1、Fin-R1)在概念漂移后容易失效,还有未公开的通用能力回退风险。
灾难性遗忘。 教模型学会证券判定,它很可能退化掉原本的通用中文能力——而「不发生灾难性遗忘」在这个课题里是硬指标,不是加分项。
这三个问题不能靠单点技巧各打各的,整套方案的设计本质上就是对它们的连续回答。
技术栈
离线侧以 Python 为主:数据清洗用 data-juicer 算子串联;短视频解帧用 FFmpeg + pHash 做场景变化检测;中文语音转写用 Paraformer/FunASR;截图理解用 Qwen3-VL(内置 OCR);微调底座选 Qwen3-14B/32B,用 LlamaFactory 跑 LoRA + 回放 + 蒸馏;双轨评测纯 Python 标准库手写,不引 sklearn/numpy。在线研判平台的方案里还会用到 FinBERT 做相关性粗筛,BGE-M3 + Elasticsearch 9 + BGE-Reranker-v2 做 RAG 知识服务。

整条链路按能力拆成五类模型:文本判定(Qwen3)、截图理解(Qwen3-VL)、语音转写(Paraformer/FunASR)、向量召回(BGE-M3)、重排(BGE-Reranker-v2),每类只做自己最擅长的一段。
没有公开仓库或在线演示页面,这里不提供 repoUrl 或 demoUrl。可公开联系入口保留在 GitHub 主页。
架构:一条主线、两层协同
整套方案是一条主线、两层协同。离线训练工具链负责把原始社交数据冷启动加工成语料、训出领域模型;在线研判平台负责消费模型对外提供研判能力。两层共享同一套领域知识——离线给数据打标、在线做粗筛核验,两边同源;也共享同一根可解释性轴——离线是训练目标里的「推理依据」段落,在线是每条判定的证据链与 trace 溯源,是同一根轴的两端。
下面按离线工具链的几个核心模块展开。
1. 数据接入与多模态清洗。 接入层把 9 平台、7 种内容类型的原始记录统一映射成标准样本结构(文本/图片/视频/音频四类字段 + 溯源元数据)。清洗在 data-juicer 流水线里以算子串联:去 HTML、繁简归一(t2s)、修复乱码、清隐私串,再接语种过滤、违规词比例过滤、长度过滤,最后用 SimHash 近似去重消除刷屏重复。
短视频不上端到端视频大模型,而是拆成三路分解管道:FFmpeg 解帧 + pHash 场景变化检测,只在画面相似度低于阈值时截关键帧,把帧数压到暴力抽取(每秒 24–30 帧)的零头;FFmpeg 抽音轨后走 Paraformer/FunASR 中文 ASR,产出带时间戳文本;关键帧送 Qwen3-VL 识别字幕、白板、股票代码。三路按帧序号 / 时间戳对齐汇总,每一路证据都能独立溯源。
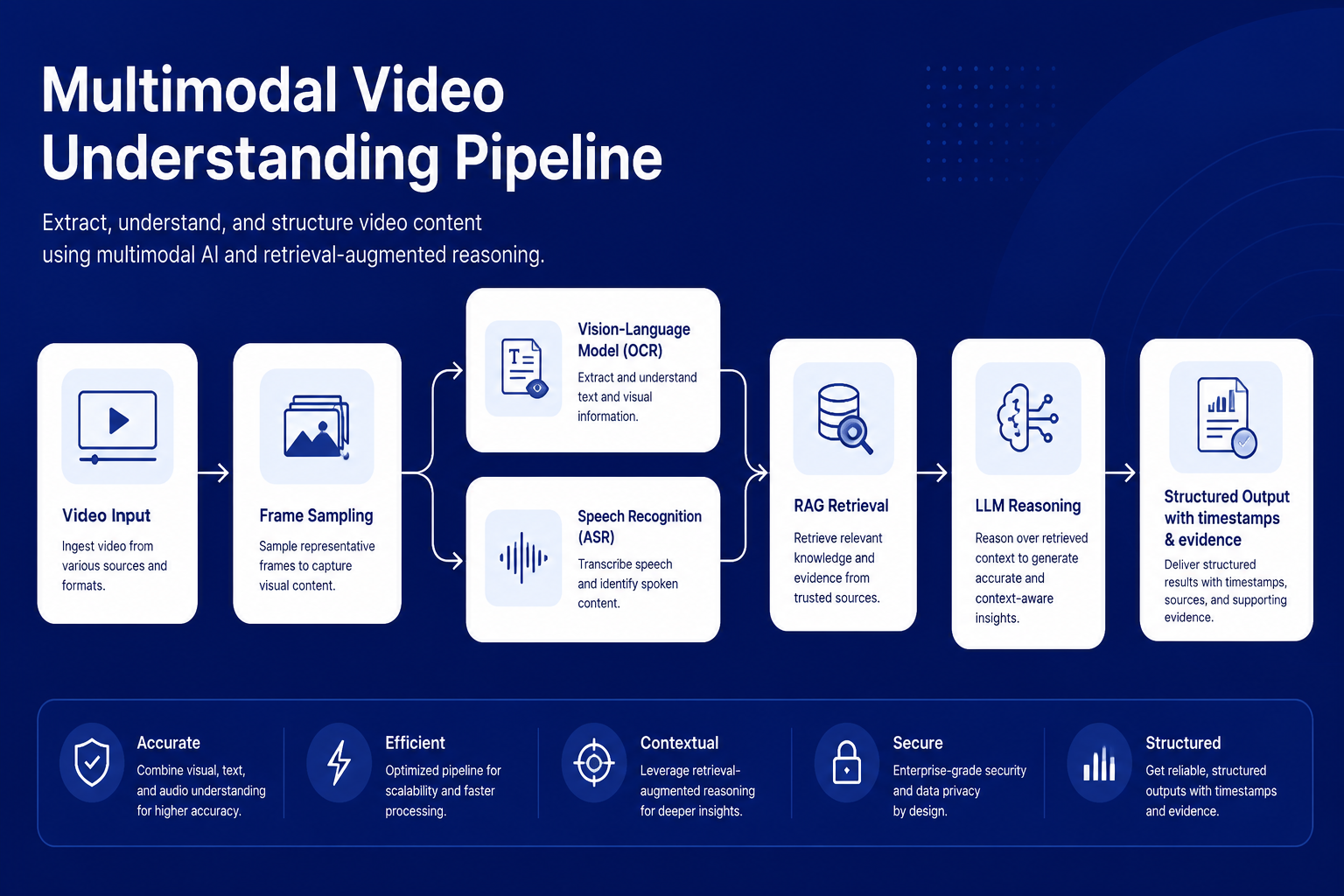
短视频被拆成抽帧、截图理解(VLM/OCR)、语音转写(ASR)三路并行,再汇总成带时间戳的结构化证据,每一路都能单独回溯。
2. 领域词典 + 统一识别引擎。 领域知识不写死在代码里,而是沉淀成 5 本可维护电子词典(荐股黑话、谐音变体、承诺话术、风险实体、违规词),扩黑话只需改文本加一行。识别引擎对外只有一个统一入口:输入文本,输出一份扁平特征字典(黑话密度与命中、风险实体计数、是否含联系方式、承诺话术强度等)。下游标注、训练、在线粗筛都从同一入口取信号,保证同源。
3. 冷启动弱标注。 因为数据无标签,用「规则打分 + LLM 投票 + 专家复核」三层联合产出第一批金标集。规则引擎按加权信号给违法/合规/存疑标签——含联系方式诱导权重最强,黑话密度、承诺话术次之;LLM 独立投票与规则做共识;低置信样本自动导出给专家复核,回填成金标集。
4. 训练样本与可解释性目标。 弱标注结果转成 LlamaFactory 的 alpaca 格式,每条样本目标输出是 <think>{中文推理依据}</think>{最终判定},复用 Qwen3 原生 <think> 思维链标记。模型不仅要给出「违法/合规/存疑」,更要用中文说清为什么。可解释性在这里是训练目标本身,不是事后附加的功能。
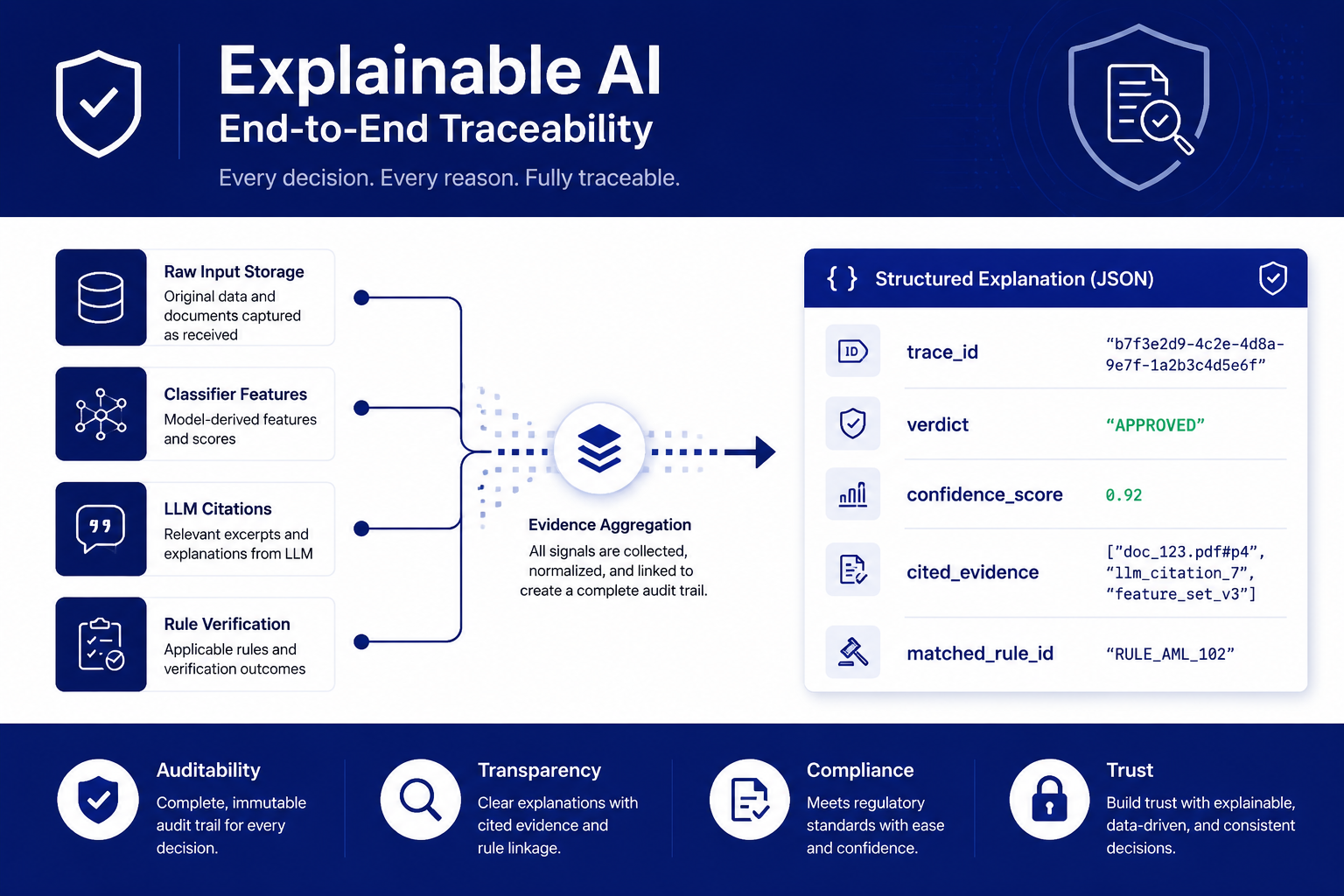
同一根可解释性轴的在线端:原文、特征、模型依据、规则核验汇成一条结构化解释。图中判定、trace_id、置信度、命中规则等字段为结构示意,演示阶段的取值来自规则引擎,非训练模型的效果数据。
5. 模型选型与防遗忘三层。 底座选 Qwen3-14B/32B:中文金融推理强、Apache-2.0 可商用闭源交付、原生「思考/不思考」双模、LlamaFactory 一等支持。防遗忘三层叠加、全用 LlamaFactory 原生配置(不改上游源码):LoRA 增量微调(lora_target: all、lora_rank: 32),冻结底座只训旁挂低秩补丁;通用语料回放(interleave_probs: 0.85,0.15),按 85%/15% 交错复习通用语料;知识蒸馏(ASFT≈LwF,KL 正则,asft_alpha: 0.2),每步 loss = 任务 loss + α·KL(新模型‖冻结 base),偏离太多就被拽回。
6. 双轨评测。 监管场景里「模型好不好用」是两件必须分开测的事。领域准确度:在金标集上算三分类的准确率、召回、F1,并单独算「判定依据正确率」(字符级 Jaccard 比对模型依据与专家依据)。通用能力保持度:用一组与证券无关的通用题,让 base / tuned 分别作答,核心看 regressions(原本会、训完不会)。评测全用 Python 标准库手写、公式可手算复核,专门处理 unknown gold(不计 FP)与 excess gold(计 FN)两个易错边界。
我负责的部分
- 设计并实现整条离线训练工具链:数据接入与多模态清洗、领域词典与统一识别引擎、冷启动弱标注、训练样本生成、训练配方与防遗忘、双轨评测、一键 CPU 端到端 demo。
- 把短视频处理设计成抽帧/转写/截图三路分解管道,控制下游视觉模型算力,并让每路证据可独立溯源。
- 把领域知识沉淀成可维护词典 + 单一入口识别引擎,把「只归一一次再分发」作为对抗谐音变体的关键设计。
- 设计弱标注的三层联合判断,加上「强规则不被 LLM 默默盖过、宁可多送人工」的安全护栏。
- 把可解释性做成训练目标本身:训练样本输出为
<think>推理依据</think>判定。 - 选定 Qwen3 底座,配好 LoRA + 回放 + 蒸馏三层防遗忘,不改上游框架源码。
- 用纯标准库手写双轨评测,把领域准确度与通用能力保持度都变成可手算复核的数字。
- 主导在线研判平台的整体链路方案设计(文本三阶段漏斗、多模态视频理解、RAG 知识服务、全链路溯源)——这部分是方案设计,不是已上线系统。
难点与处理
短视频该不该上端到端视频大模型。 端到端模型省事,但算力贵、证据不可拆。我拆成抽帧/转写/截图三路,配 pHash 只在场景变化时截关键帧,把帧数压到暴力抽取的零头,既省算力又让每路证据可独立溯源。代价是三路要按帧序号/时间戳对齐,工程上更碎,但这笔账在监管场景里是划算的——证据可拆比省工程量重要。
谐音变体怎么不被绕过。 如果每个检测器各自做归一化,威信/微信、扣扣/QQ、飞机/Telegram 会被不一致地处理,漏判风险高。我把 NFKC 全角转半角 + 去零宽 + 谐音还原集中做一次再分发,保证所有检测器看到的是同一份归一文本。风险实体识别里还内置手机号正则、A 股 6 位代码和进群二维码诱导模式。「含联系方式诱导」往往是整条话术里最强的违规信号,归一不一致就会把它漏掉。
弱标注的安全护栏往哪偏。 可以让 LLM 投票盖过规则、追求自动化率;但监管场景宁可多送人工、不可漏判。所以当强规则判「违法」而 LLM 相左时,系统强制判「存疑」并送审,存疑置信度被刻意压低封顶、确保被路由到人工。这偏保守,牺牲一点自动放行率,换来召回不被悄悄牺牲。
底座要不要直接拿金融垂类模型。 DianJin-R1、Fin-R1 这类窄域强化模型领域能力强,但有未公开的通用能力回退风险,与「不灾难性遗忘」硬指标冲突。我把它们留作对照基准,底座选通用的 Qwen3,再用三层防遗忘把领域能力加上去。
领域适配要不要 fork 上游。 fork 改得最自由,但每次上游升级都要痛苦合并。我选 overlay 模式:上游数据处理与微调框架原样保留、绝不修改,所有领域改造放自己的包里,只通过两个工具各自官方的扩展点挂接,上游升级 git pull 就能跟上。包内守一条分层纪律——领域逻辑全集中在纯标准库核心层(无需 GPU、无需重框架即可秒级单测),框架适配层只做胶水。
评测要不要引库省事。 引 sklearn/numpy 省代码,但监管场景要求公式可手算复核、可审计。我手写三分类指标和遗忘四象限,专门处理 unknown gold / excess gold 边界,代价是多写代码,换来每个数字都能被业务方手算验证。
如何运行
整条工具链由数百项自动化测试守护。一条命令即可在普通 CPU 开发机上几秒内跑完「原始数据 → 清洗 → 标注 → 训练样本 → 评测」全流程,不需要 GPU,可随时给业务方做完整 demo。训练配方与防遗忘配置已经通过 LlamaFactory 的真实解析校验,GPU 到位即可一键开训——按 14B/32B 选档,单卡需要 24–80G 显存。
后续计划
真实模型训练还没开始,在等两样东西:GPU 算力,以及业务专家复核出的金标集。在这两样到位之前,所有演示都基于规则引擎,展示的是识别能力而不是模型性能,也因此本页面不写任何效果数字。在线研判平台目前是链路方案设计,后续若有模块落地为运行代码,会再单独说明。
链接
- GitHub:github.com/JV-X
如果你正在做强合规场景下的领域大模型训练、多模态内容风控或 RAG 知识服务,可以通过页面下方微信二维码或邮件沟通,邮箱:contact@aildnc.com。