金融监管 / 内容风控 / 某证券监管科技(RegTech)课题,面向证券监管的内容风控场景
非法证券活动识别领域大模型训练工具链
非法证券活动(荐股黑话、保本保收益话术、场外配资引流、虚假持牌机构、原始股诈骗)分散在 9 个主流社交平台、横跨文本图片短视频音频,人工巡检看不过来,而通用大模型既不懂领域黑话、误报率偏高,又说不清判定依据,无法被监管采信和审计。
我主导实现了一条从社交平台多模态脏数据冷启动加工成训练语料、训出会判定非法证券活动并能用中文说出判定依据的领域大模型的全自动离线工具链,底座为 Qwen3,配 LoRA、通用语料回放与知识蒸馏三层防遗忘,并主导设计了在线消费该模型的研判平台方案。
多模态数据接入与清洗 -> 领域词典 + 统一识别引擎(只归一一次再分发)-> 规则 + LLM + 专家三层冷启动弱标注 -> <think> 推理依据 + 判定的训练样本 -> Qwen3 LoRA + 回放 + 蒸馏三层防遗忘训练配方 -> 领域准确度与通用能力保持度双轨评测 -> overlay 工程架构 -> 在线研判平台方案设计。
整条离线训练工具链已搭好并跑通,由数百项自动化测试固化,一条命令可在普通 CPU 开发机上几秒内完成「原始数据到清洗、标注、训练样本、评测」的端到端 demo;训练配方与防遗忘配置已通过 LlamaFactory 真实解析校验,GPU 到位即可一键开训。真实模型尚未训练,演示中出现的判定结果来自规则引擎,代表识别能力而非训练模型的性能。
非法证券活动识别领域大模型训练工具链,是一套把社交平台多模态脏数据冷启动加工成训练语料、训出一个会判定非法证券活动并能用中文说出判定依据的领域模型的全自动离线工程方案,底座为 Qwen3,配 LoRA、通用语料回放与知识蒸馏三层防遗忘。
背景
这是一个面向证券监管的内容风控课题。荐股黑话、保本保收益话术、场外配资引流、虚假持牌机构、原始股诈骗,这些非法证券活动大量散落在主流社交平台上,形态横跨文本、图片、短视频和音频。靠人工巡检根本看不过来。
直接拿通用大模型来判,又有两个硬伤:它不懂「老师带单 / 加 V 进群 / 原始股稳赚」这类领域黑话,误报率偏高;就算它判对了,也说不清为什么判这条违法。而在监管场景里,判得出依据、判定可被审计,和判得准是同等重要的硬要求。
客户身份对外脱敏。能说清的分量是:这是一个证券监管科技(RegTech)场景,强合规,要做多模态全量巡检,每一条判定都必须可审计。课题目标不是调一个 API,而是训练出一个真正懂证券监管语境的领域模型。
真正麻烦的地方
这件事的难,不在某个单点技术,而在三座山叠在一起,缺一个都过不去。
第一座山是数据没有标签。数据源里的帖子,没人事先告诉你哪条违法、哪条合规。监督训练连第一步都迈不出去——你想训模型,手里却一条带标签的样本都没有。
第二座山是开源模型不直接可用。通用模型缺领域知识;现成的金融垂类小模型(如 DianJin-R1、Fin-R1)这类窄域强化训练的模型,在概念漂移后容易失效,而且有未公开的通用能力回退风险。拿来即用,等于把不确定性引进了最讲究确定性的监管场景。
第三座山是灾难性遗忘。教模型学会证券判定,它很可能把原本的通用中文能力退化掉。而「不发生灾难性遗忘」本身就是这个课题的一条硬指标——不是锦上添花,是验收红线。
这三个问题不能靠单点技巧各个击破,整套方案的设计,本质上就是对它们的系统性回答。
我负责的部分
我主导了整条离线训练工具链的工程实现,并主导设计了在线研判平台的方案。这里把责任边界说清楚:离线工具链是已经搭好、跑通、被测试固化的交付物;在线研判平台目前是链路方案设计,不是已上线运行的系统。
具体到离线这条线,我做的是:把 9 平台、7 种内容类型的多模态脏数据统一成标准样本结构,用 data-juicer 算子串成清洗流水线;把短视频拆成抽帧、语音转写、截图理解三路分解管道;把领域知识沉淀成可维护词典 + 一个只有单一入口的统一识别引擎;设计规则 + LLM + 专家三层联合的冷启动弱标注,并加上强规则不被 LLM 默默盖过的安全护栏;把可解释性做成训练目标本身;选定 Qwen3 底座并配好 LoRA + 回放 + 蒸馏三层防遗忘;用纯标准库手写双轨评测;选 overlay 工程架构,绝不 fork 上游。
方案与取舍
整套东西是一条主线、两层协同。离线工具链负责把原始社交数据冷启动加工成语料、训出领域模型;在线平台负责消费模型对外提供研判能力。两层共享同一套领域知识,也共享同一根可解释性轴——领域知识在离线给数据打标、在线做粗筛核验,同源;可解释性在离线是训练目标里的推理依据段落、在线是每条判定的证据链与 trace 溯源,是同一根轴的两端。
冷启动弱标注,回答了「数据没标签」这座山。 既然没人给标签,就用三层联合判断自己造出第一批金标集:规则引擎按加权信号给出违法 / 合规 / 存疑标签(含联系方式诱导权重最强,黑话密度、承诺话术次之),LLM 独立投票做共识,低置信样本自动导出给专家复核回填。这里有一条刻意的安全护栏——当强规则判「违法」而 LLM 多数相左时,系统强制判「存疑」并送人工,绝不让 LLM 默默盖过强规则。监管场景宁可多送人工,不可漏判。这偏保守,牺牲了一点自动放行率,换来召回不被悄悄牺牲。
三层防遗忘,回答了「灾难性遗忘」这座山。 底座没有拿现成金融垂类模型起步,选了通用的 Qwen3-14B/32B,再用三层叠加把领域能力加上去,全部用 LlamaFactory 原生配置实现、不改上游源码:LoRA 只训旁挂低秩补丁、冻结底座(lora_rank: 32、lora_target: all);通用语料回放按 85% / 15% 交错复习通用语料(interleave_probs: 0.85,0.15);知识蒸馏(ASFT≈LwF,KL 正则,asft_alpha: 0.2)把偏离冻结底座太多的更新拽回来。设计哲学是先用框架原生能力解决到位,不够再加,把可量化验证放在堆复杂正则之前。
可解释性做成训练目标,回答了「判定要可审计」。 训练样本的目标输出不是一个干巴巴的标签,而是 <think>{中文推理依据}</think>{最终判定},复用 Qwen3 原生的 <think> 思维链标记。模型先讲依据、再下结论。可解释性不是事后附加的功能,是训练目标本身,直接对应在线侧每条判定的证据链与 trace 溯源。
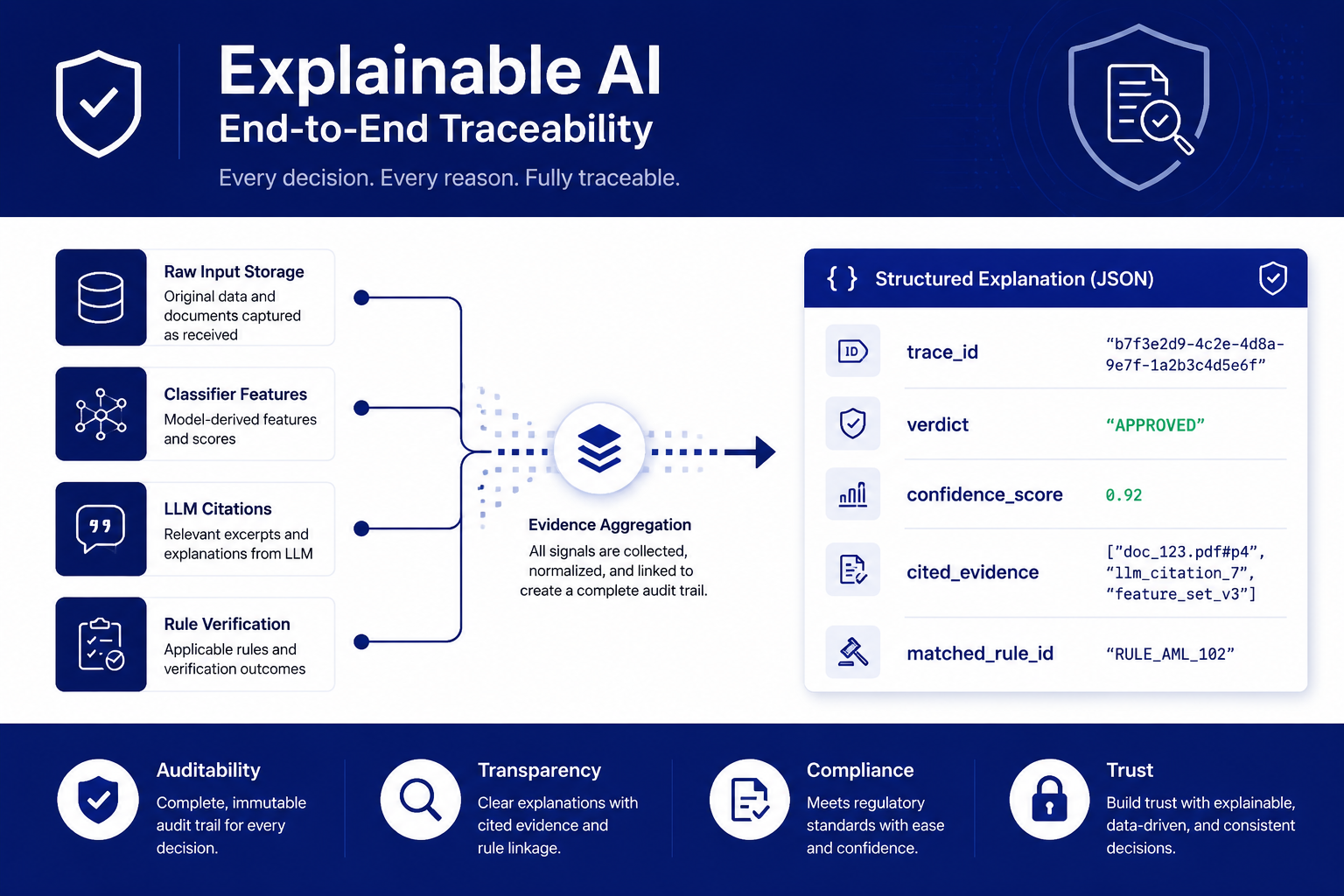
每条判定在线上都被设计成一条可回溯的结构化解释:原文、特征、模型依据、命中规则汇到一起。图中的判定、置信度、trace_id、命中规则等字段均为结构示意,演示阶段取值来自规则引擎,不代表训练模型的效果。
几处更细的取舍,方向都一致:宁可工程上更碎,换可控和可审计。短视频不上端到端视频大模型,而是拆成抽帧 + 转写 + 截图三路,配 pHash 只在场景变化时截关键帧,把帧数压到暴力抽取的零头,既省算力又让每路证据可独立溯源,代价是三路要按帧序号 / 时间戳对齐。识别引擎坚持只归一一次——文本先做 NFKC 全角转半角、去零宽字符、谐音变体还原(威信→微信、扣扣→QQ、飞机→Telegram),再分发给所有检测器,保证对抗变体被一致识破,而不是让每个检测器各归一各的、留下漏判口子。评测全部用 Python 标准库手写、不引 sklearn/numpy,专门处理 unknown gold(不计 FP)与 excess gold(计 FN)两个易错边界——监管要求公式可手算复核,引库省事但换不来可审计。
结果与边界
这一节得实话实说,因为它直接关系到这个案例的可信度。
离线训练工具链已经搭好并跑通:数据接入与多模态清洗、领域识别能力、冷启动弱标注 + 专家复核闭环、训练配方与防遗忘配置、双轨评测框架、一键 CPU 端到端 demo,都已被数百项自动化测试固化。一条命令就能在普通 CPU 开发机上几秒内跑完「原始数据 → 清洗 → 标注 → 训练样本 → 评测」全流程,无需 GPU,随时能给业务方做完整演示。训练配方与防遗忘配置已经通过 LlamaFactory 的真实解析校验,GPU 到位即可一键开训。overlay 架构守住了「不能直接交付开源现成」的验收要求:上游零修改,领域改造全部走官方扩展点。
但真实模型还没训练。在等两样东西:GPU 算力(单卡 24–80G,按 14B / 32B 选档)和业务专家复核出的金标集。在这之前,演示里出现的判定结果来自规则引擎,代表的是识别能力,而不是训练模型的性能。所以这个案例里没有任何模型效果数字——没有准确率、没有召回、没有误报率下降。把规则引擎演示包装成模型性能,是我不会做的事。在线研判平台(文本三阶段漏斗、多模态视频理解、RAG 知识服务、全链路溯源)目前也是链路方案设计,不是已上线运行的系统。
经验判断
做强合规场景的 AI,最容易踩的坑是把演示效果当交付效果。规则引擎能跑出一份漂亮的判定,不等于训练出来的模型就是这个水平。把这两件事分开讲,短期看像是少了卖点,长期看才是这类客户愿意继续合作的基础——监管业务方比谁都清楚,一个说不清边界的供应商更危险。
另一个判断是,监管场景的工程取舍几乎总是偏保守的那一边。自动放行率、端到端的省事、堆更复杂的正则,这些在别的场景是加分项,在这里要先让位给可审计、可手算复核、宁可多送人工。把这条想清楚,很多技术选型就不纠结了。
相关链接
如果你正在做监管科技、内容风控、领域大模型训练或多模态识别相关的项目,可以通过下方微信二维码或邮件沟通,邮箱:contact@aildnc.com。
联系
讨论类似项目
如果你正在评估类似的文档解析、企业 RAG、知识库或 AI 工作流,可以先发问题背景。 微信沟通优先,邮箱也可以:contact@aildnc.com。
 扫码加微信沟通
扫码加微信沟通