文章
体检报告流水线里的 AI,难点不在生成,而在边界控制
结合一套连锁体检机构 AI 报告流水线的工程复盘,讨论智能推项、科普、建议和矛盾识别为什么必须把边界控制写进系统。
很多人提到医疗场景里的 AI,第一反应是模型要不要更强,或者 prompt 要不要再细一点。真落到体检报告流水线里,我的感受刚好相反: 最麻烦的部分通常不是“让它写出来”,而是“让它不要写过头,不要写歪,也不要把看起来顺的错误一路传下去”。
我参与并维护过一套面向某年服务数十万体检场次的连锁体检机构客户的报告流水线 AI。它不是一个聊天助手,而是四段彼此相关的生成链路: 智能推项、科普、建议、矛盾识别。把这四段拆开看,问题都不算抽象;真正难的是把它们接到同一套业务边界里。
这类系统的核心,不是会写,而是不能乱写
上一代系统里,“科普 + 建议”仍然需要医生人工撰写,单份大约 3 分钟。规模一上来,问题就不只是人手,而是不同医生写法不同、对外文书风格不统一、模型可能给出带承诺意味的表述,或者把并不存在的项目名、项目编码和价格拼进结果里。
所以这个场景里最先要解决的,不是如何把回答写得更像人,而是先把几类风险拦住:
- 推荐结果必须能落到本院真实项目库,不能只看起来合理
- 科普不能写成安抚式承诺
- 建议要像机构医生写出来的文书,而不是聊天机器人回复
- 矛盾识别要分得清真矛盾和医学上可共存的差异
如果这些边界没有工程化,再流畅的输出也只是更危险的自动补全。
智能推项不能只靠模型拍脑袋
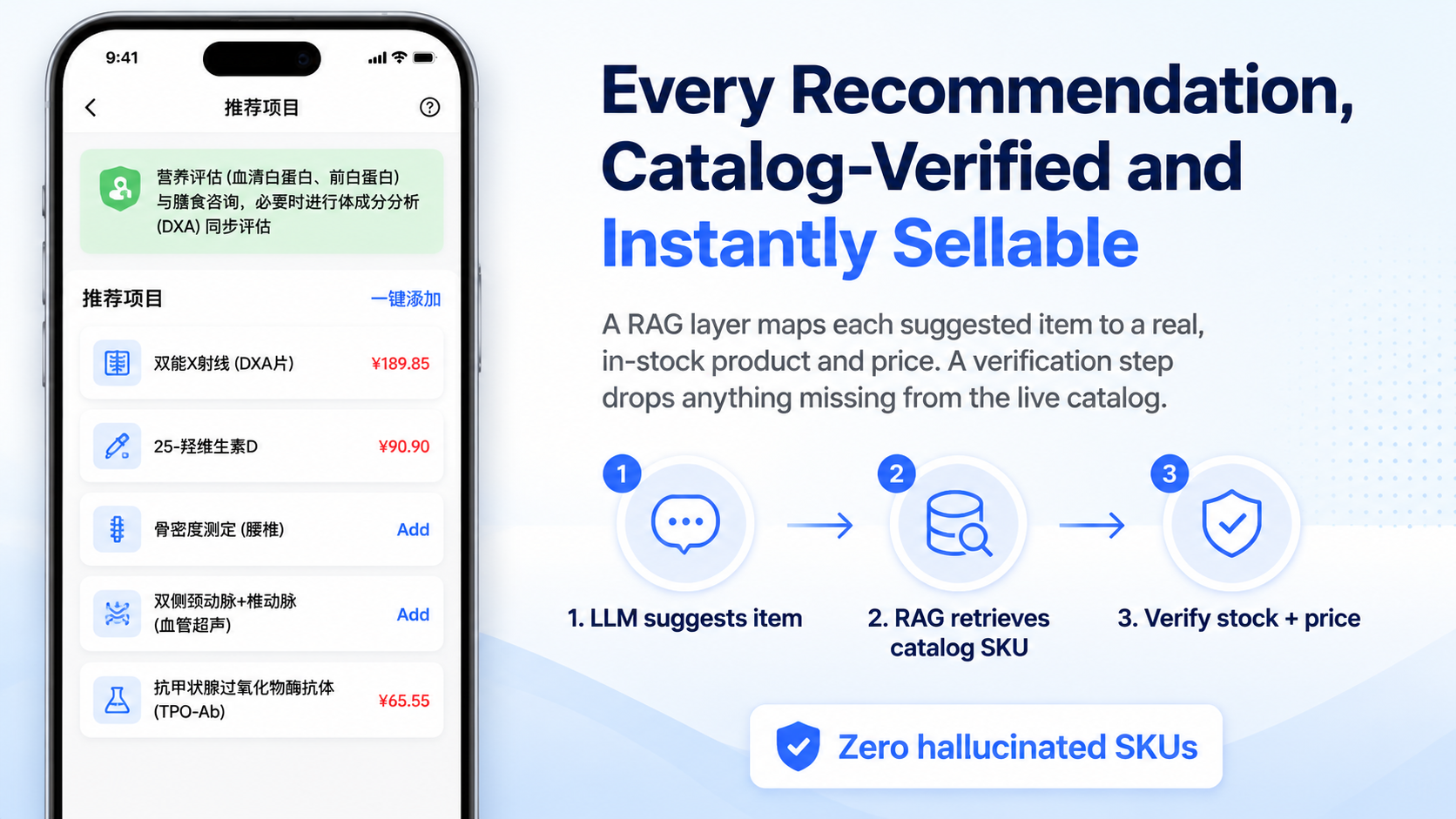
体检推项最容易被低估的一点,是“推荐对不对”和“能不能落库”是两回事。
这条链路没有让模型直接吐最终项目,而是拆成了思考、抽取、检索、映射、质检几段。模型先给出推荐思路,再抽取项目名,再去检索本院真实项目,最后把推荐结果映射回本院可用字段。
这里最关键的是最后一道 quality_control。系统会拿模型输出的 projectId、projectCode、projectName 回查 relation_items。对不上,就把 projectId、projectCode、projectPrice 清空。
这个动作看起来很笨,但我一直觉得它比“尽量猜对”重要。因为在报告类系统里,宁可前端少展示一点,也不能让模型编出来的项目编码和价格透传出去。
推项侧还维护了二十余类专项筛查,运行时会用 ThreadPoolExecutor(max_workers=20) 并发做风险评估。这样的设计很直接,但代价也很明显: 规则表需要持续维护,业务覆盖范围一变,工程侧就得跟着改。
科普和建议看起来像写作,实际上更像规则系统
很多人会把这类任务理解成“把医生示例喂给模型,让它模仿语气”。这在体检场景里不太稳。
我更认同的做法,是把风格和边界拆成显式规则。
比如科普侧,有 5 条强禁词,核心都指向一类过度安抚、带承诺意味的表达。原因不是它一定对应已经发生的投诉,而是这种话一旦进入体检报告,用户会把它理解成业务承诺,边界立刻变得很危险。
建议侧的约束更具体一些:
- 只能落在三类里: 专科就诊、进一步检查、复查
- 一条建议只能归属一个科室
- 明确排除急诊科
- 复查时间区间取最短
- 数字统一用阿拉伯数字
这些规则听起来不像“AI 创新”,但它们决定了输出是不是像机构医生写出来的正式文书。比如“肺结节,建议 1 个月复查”和“是肺结节,于一个月复查”,信息差不多,文书感完全不一样。
我后来越来越少在这种场景里依赖 few-shot。因为 few-shot 不只会传递语气,也会把疾病、部位、数值这些具体内容一起带偏。规则更笨,但更可控。

矛盾识别最难的地方,是假矛盾比真矛盾更消耗系统
如果只看字面,矛盾识别像个标准的 LLM 判断题: 找出前后冲突的描述,给出结构化结果。但体检报告不是普通文本对比,很多“看起来不一致”的描述,在医学上是可以共存的。
这条链路最后做成了 4 路并发: 科间、科间性别、科内、历史。后来历史分支因为长上下文会稀释注意力,被注释禁用。剩下的链路里,每一路都不是一步出答案,而是三段:
- 先做自然语言分析,找可能冲突的点
- 再转成结构化 JSON
- 最后做二次审核和豁免
其中一个很现实的细节是,JSON 阶段最多会重试 5 次,每次把上轮输出再塞回上下文,让模型修格式。这不是优雅方案,但在当时模型能力和算力条件下,是能把链路跑稳一点的土办法。
更关键的是豁免规则。系统里后来沉淀了 13 个具名假矛盾豁免案例,用来处理那些会反复误报的场景。
我印象比较深的是血压复测规则。比如原始血压异常,第一次复测也异常,但第二次复测正常,业务上就按正常处理。如果模型只盯着最前面的异常值,很容易把小结里的“血压正常”判成矛盾。这个问题不靠“更聪明的模型”自动消失,最后还是要把规则反复写进 prompt 和二次审核逻辑里。
平台和工作流不是越重越好
这套系统早期也尝试过把更多逻辑放进 Coze 一类工作流平台里,后来又回退到“vLLM 做主推理,Coze 只承接检索类子任务”的组合。
原因很简单: 这个业务真正复杂的不是节点怎么连,而是推荐贴合度、医学边界、误报处理、输出文书风格这些细节。如果把它们全部塞进工作流平台,编排本身会变成新的复杂度。
还有一个更具体的工程信号。客户内网部署时,Coze 代码节点沙盒冷启动大约 3 秒/次。这个量级一出现,你就会很清楚哪些步骤适合放平台里,哪些步骤不该继续往里塞。
所以我现在看工作流选型,越来越少问“能不能全放进去”,更多问“哪些部分真的需要平台能力,哪些部分应该留在更可控的服务层里”。
我对这类医疗 AI 的一个判断
做体检报告流水线,不太像在做一个会聊天的产品,更像在做一条受约束的内容生产线。模型当然重要,但更重要的是你有没有把这些问题提前写进系统:
- 推荐结果如何回到真实项目库
- 哪些表述绝对不能出现在报告里
- 文书风格如何稳定,不被模型自由发挥带偏
- 假矛盾如何持续沉淀成规则
- 长上下文和多轮调用带来的格式失败、误报和延迟怎么处理
这类系统的价值,往往不在某一次输出看起来多聪明,而在它能不能长期维持边界、减少误报,并且在业务变动时还能继续被维护。
如果你正在做企业 RAG、知识库、AI 客服或 Agent 工作流,可以通过页面下方微信二维码、网站 https://www.aildnc.com 或邮件沟通,邮箱:contact@aildnc.com。