项目
体检报告流水线 AI 助手
一个面向连锁体检机构的报告流水线 AI 项目,覆盖智能推项、科普、建议和矛盾识别四类生成任务。
这个项目服务于某年服务数十万体检场次的连锁体检机构客户。它不是一个面向 C 端的聊天助手,而是一组嵌入体检报告流水线里的生成链路:体检前做智能推项,报告阶段生成科普和建议,同时检查报告内部是否存在明显矛盾。
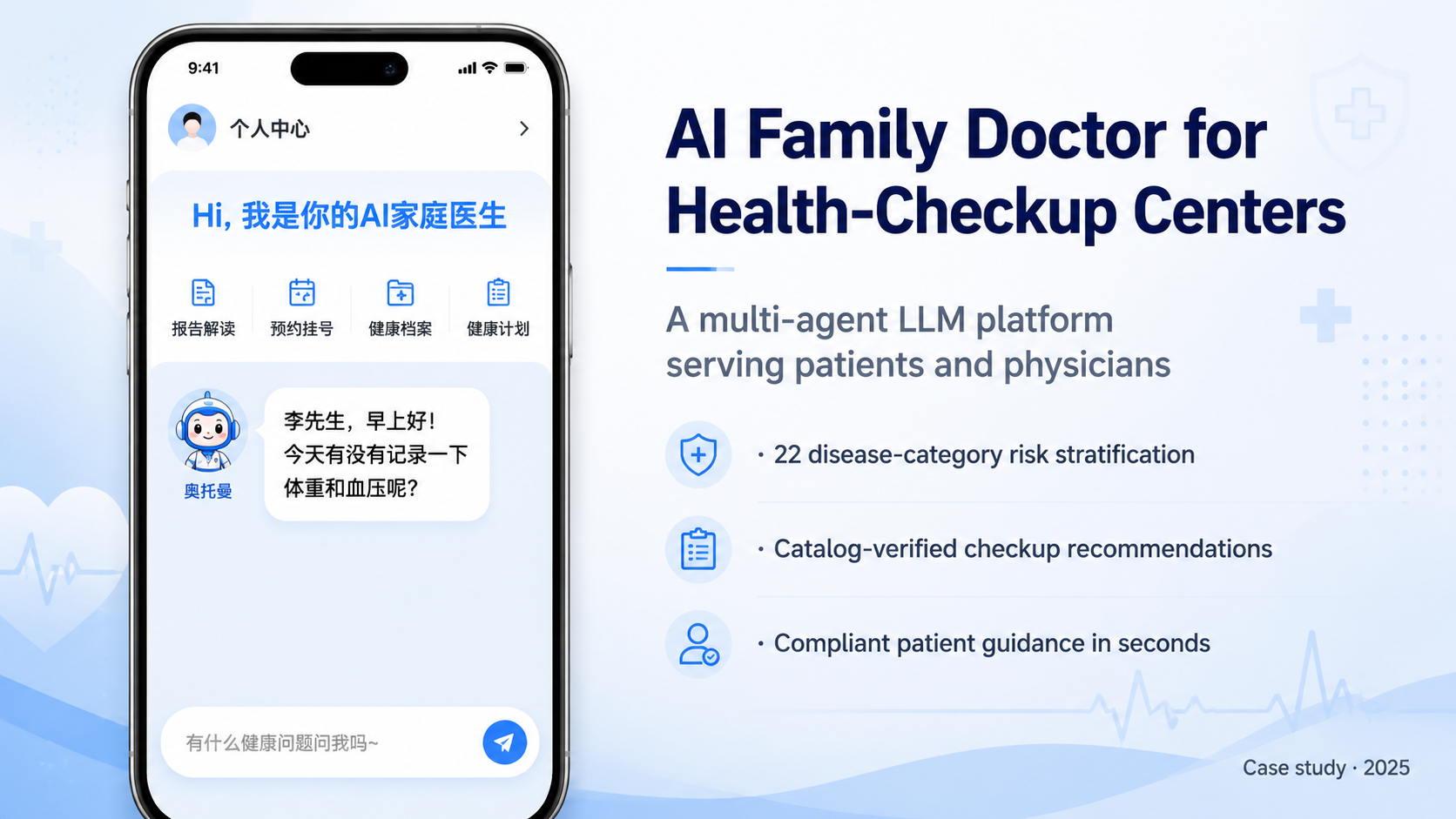
我在这个项目里更接近参与和维护部分链路的工程角色,而不是从 0 到 1 主导整套系统。下面这页也按这个边界来写,只展开我能确认的模块、规则和取舍。
问题定义
这个项目真正难的地方,不是“让模型写点医学文本”,而是让输出能进入正式报告流程。
- 推项结果必须落到机构真实可挂、可计费、可展示的项目库,不能只给一个看起来合理的名字。
- 科普内容不能越界,尤其不能出现承诺式、安抚式表述,削弱用户继续检查或随访的必要性。
- 建议内容要像机构医生写出来的报告用语,而不是聊天机器人式回复。
- 矛盾识别不能只做字符串对比,很多看起来不一致的描述,在医学上其实可以共存。
上一代系统里,单份“科普 + 建议”仍然由医生人工撰写,平均要花约 3 分钟。客户量级一上来,问题就变成了如何把这些环节拆成可控、可复核、可持续迭代的工程链路。
架构与模块
整套流水线里,可公开的核心模块有四类。
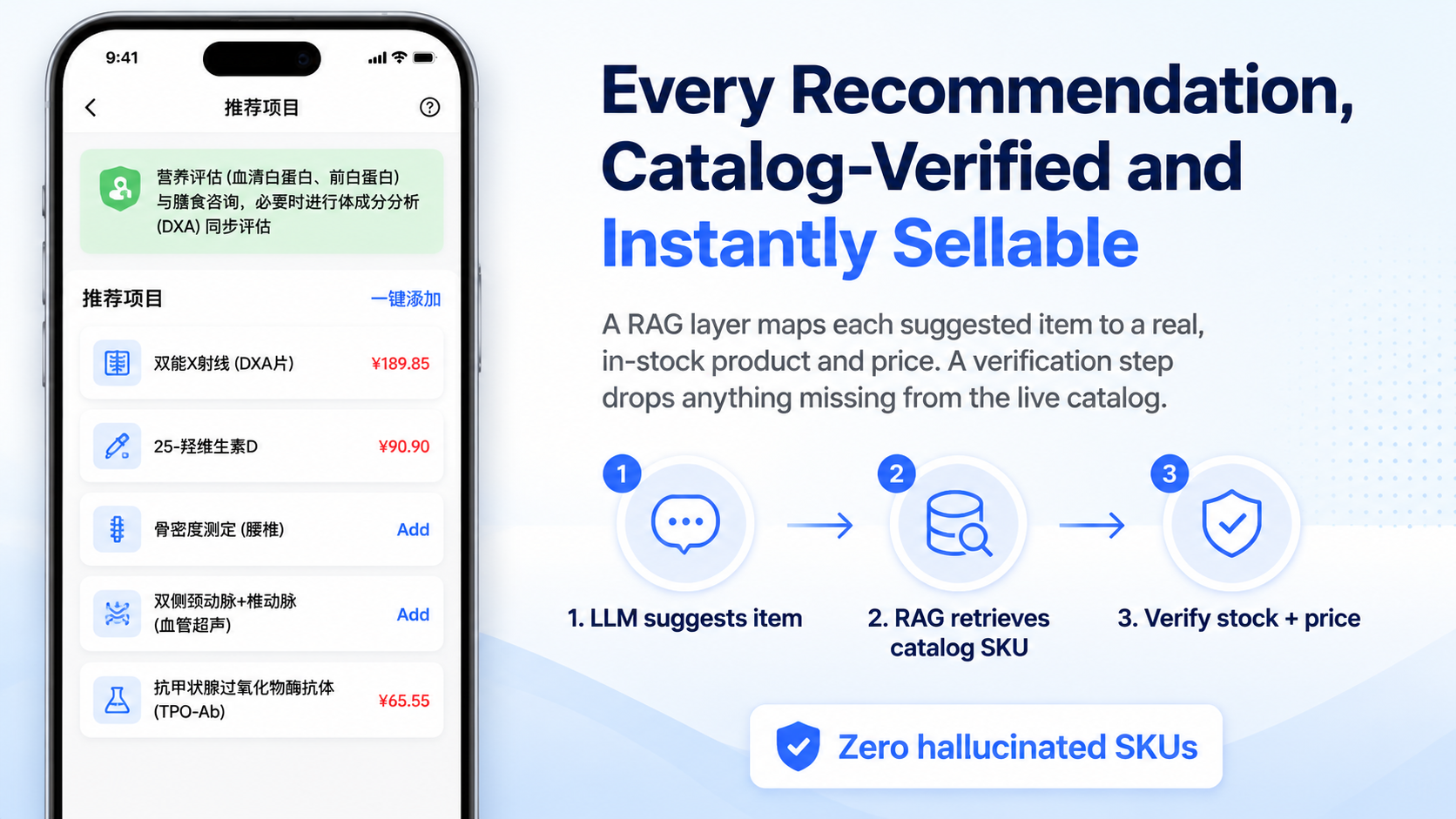
智能推项
推项没有直接让模型吐最终项目,而是拆成了几段:
- 先生成健康情况和推荐思路。
- 从自然语言里抽取项目名。
- 并发调用检索类子工作流,找机构已有项目。
- 把推荐结果映射到本院项目字段。
- 最后由
quality_control回查项目库,对不上就清空关键字段。
这里的重点不是让模型“会推荐”,而是宁可少展示,也不能让虚构的 projectId、项目编码或价格继续往下游透传。
科普与建议
科普和建议都不是一份固定 prompt,而是配置驱动的生成链路。工程上保留了不少硬规则:
- 科普侧有 5 条强禁词,用来拦住承诺式和过度安抚式表达。
- 建议侧只允许三类输出:专科就诊、进一步检查、复查。
- 一条建议只能归属一个科室。
- 复查时间区间取最短,数字统一用阿拉伯数字。
- 急诊科被显式排除。
这些规则的价值在于把文书风格收紧,让输出更像机构报告,而不是像开放式问答。
矛盾识别
矛盾识别走的是 4 路并发设计:科间、科间性别、科内、历史。历史分支后来因为长上下文注意力稀释问题被注释禁用。
每一路内部又分三段:
- 先做自然语言分析,找可能冲突的点。
- 再提取结构化 JSON,方便系统消费。
- 最后走二次审核和豁免,把医学上可共存的差异排除掉。
这条链路里沉淀了 13 个具名假矛盾豁免案例,还专门处理了血压复测这类容易误报的规则场景。
工作流平台取舍
项目早期试过把更多逻辑塞进 Coze 工作流,后来又回到“vLLM 主推理 + Coze 只做检索类子任务”的组合。原因很现实:这个业务最复杂的部分不在节点编排,而在推荐贴合度、业务边界和误报控制。再加上客户内网部署时,Coze 代码节点沙盒冷启动约 3 秒/次,工作流层本身也开始变成延迟来源。
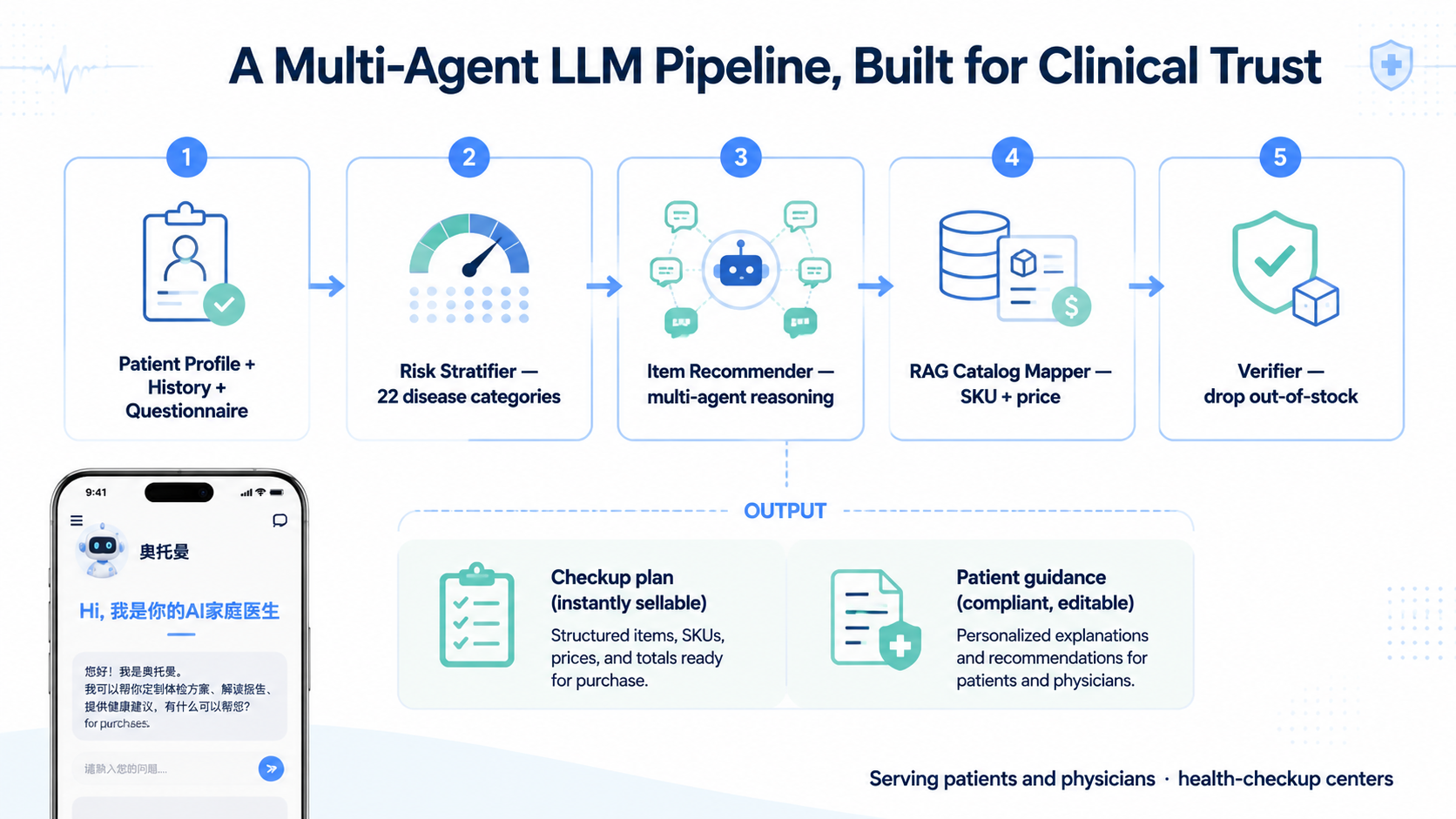
我负责的部分
能确认写进项目页的部分主要有这些:
- 参与并维护过智能推项、科普、建议、矛盾识别四类生成链路的工程复盘和规则梳理。
- 梳理并保留了推项链路里的“思考、抽取、检索、映射、质检”分段设计。
- 梳理
quality_control对模型输出项目字段的反查逻辑,对不上机构项目库就清空关键字段。 - 梳理矛盾识别的 4 路并发、三段式 LLM 链、5 次 JSON 重试和 13 个豁免案例。
- 梳理科普和建议里的 prompt 约束,包括禁词、三选一、急诊科排除、时间表达和科室归属规则。
- 参与总结从 Coze 重工作流思路退回到“主推理 + 检索子任务”的工程取舍。
这里没有把医生规则、客户判断或全部团队实现写成个人成果,这是我刻意保留的边界。
难点与处理
第一类难点是幻觉不能直接进报告。
推项链路最后一定要回到机构项目库做反查。对不上的字段直接清空,会牺牲一部分召回,但能把风险挡在展示层之前。
第二类难点是长 prompt 会稀释模型注意力。
矛盾识别的结构化阶段用了最多 5 次 JSON 重试,并把上轮输出累积回上下文。这做法不优雅,但在当时模型和算力条件下,比单次失败后直接放弃更实用。
第三类难点是医学文书的“像不像”不能只靠 few-shot。
这类场景里,示例很容易把具体疾病、部位和数值一起带偏,所以项目更依赖规则集来锁风格,比如阿拉伯数字、单条建议单科室、时间区间取最短等。
第四类难点是误报处理很难一次性抽象干净。
矛盾识别最后还是沉淀成了白名单式豁免案例。它不够优雅,但能把真实线上误报收敛成工程规则,先解决业务问题。
后续计划
从这次可公开复盘暴露出的边界看,这个项目后面还有几件事值得继续做:
- 继续把规则层和模型层拆开,减少 prompt 版本迭代带来的回归面。
- 给矛盾识别补更稳定的结构化输出约束,降低多次 JSON 重试的依赖。
- 重新评估历史矛盾分支是否能在更合适的上下文管理下恢复。
- 把工作流平台只保留在真正适合的检索型子任务里,避免把编排本身做成新的复杂度。
这个项目给我的一个长期判断是:医疗类生成系统里,真正决定能不能上线的,往往不是模型会不会写,而是规则、校验、边界和回退机制够不够扎实。
如果你正在做企业 RAG、知识库、AI 客服或 Agent 工作流,可以通过页面下方微信二维码、邮箱 contact@aildnc.com,或访问 aildnc.com 沟通。